操作系统
Lecture 1-1
Prerequirement
- Assembly,C,Data Structures
- Programming skills:
- C programming language
- Linux Programming and Debugging
Grading
- Final Exam 50
- Project 50
- Implement Linux0.11 on RISCV 64bit
Lab
实现Interrupts
manual:http://zju-sec.github.io/os22fall-stu
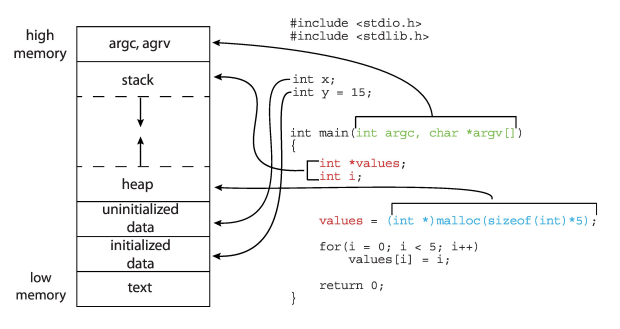
Data Stored in Memory
- 内存的基本单元是byte,一个byte有8个bits
- 每一个byte在内存中有一个地址
- 所有的地址在机器中有相同的位数
- processer是对地址上的数据进行操作
- 地址上的数据的意义由解读而不同,可以是一个数、一个ascii码...
- 操作系统没有数据类型,都是一个地址和一个数据
- 指针:指向地址
- 强转:强制解释数据
- 操作系统中最常用的结构是数组。
- 为了避免data和instruction混淆,我们人为将memory分成了存code和data的地方,但是这仅仅是人为的,会发生注入攻击
Lecture 1-2
Review
CPU
- 读取和修改内存的硬件
- 里面有什么东西
- ALU
- Control Unit
- PC:program counter,指向下一条指令的地址
- Current Instruction
- 32个寄存器
- 执行的步骤
- Fetch:从PC指向的内存地址取出内容,放入current instruction,PC+1
- Decode:解码指令
- Execute:执行指令
DMA
- DMA在现代电脑中广泛应用
- CPU准许memory和IO直接进行数据传输
- 比如拷贝数据从memory到memory
- 一般的做法是memory通过总线先到CPU再写道memory,效率很低
- 能不能不用CPU,直接进行拷贝
- DMA Controller能够直接对内存里的数据进行传输,不通过CPU
- DMA不是完全自由的,也需要占用CPU
- 信号的传入
- 占用Memory Bus
- 比如拷贝数据从memory到memory
Memory Hierarchy
- CPU(Register):如4Ghz的执行一条指令仅需0.25ns
- Cache:1ns左右
- Memory:400ns左右
- I/O,Disk:5ms左右
- 多层Cache(L1,L2,L3)
Cache为什么work?
- Temporal Locality
- 访问的东西再最近的时间还会再访问
- Spatial Locality
- 访问的地址最近还会再访问
Moore's Law
什么摩尔定律失效了?发热问题难以解决
SMP System
- Symmetric multi processors对称多处理器
- 多处理器
Multi-core Chips
- core之间的交流需要开销,50个2Ghz的cores远远不如1个100Ghz的core
- 处理器中多核
OS
- What is OS?
- 操作系统,可以说是硬件的管家
- Resource abstractor抽象资源
- Resource allocator管理资源
- 决定了哪些软件可以获得哪些资源
- 如何启动操作系统?
- 先启动第一个程序bootstrap program
- Stored in ROM
- Bootloader:初始化电脑,定位启动操作系统的kernel即Head.S
- kernel启动第一个进程,在linux中叫做init
- 之后kernel就不做任何事,等Event事件发生,占用一点内存,因此设计要简单
- kernel不是一个running job
- 先启动第一个程序bootstrap program
- Multi-Programming:现在的OS能做很多个进程job
- OS在memory中找一个任务进行执行,这个任务需要等待其他事务时,进行进程转换,做另一件事
- 这就是context-switch
- Time-Sharing:Multi-Programming with rapid context-switch
- jobs不能跑太久,把任务分的很小
- 允许interactivity
- 反应时间要短
- 每一个job有一种illusion在系统上独立的
- 进程:需要进行的任务
Running OS
- Lean:nothing more,资源管理角度,要简单
- Mean:single minded,没有程序为os修复,因此代码稳定性要好,不能有bug
操作系统如何管理硬件资源
- 给Instruction设立权限
- Privileged:执行这个指令需要权限
- Unprivileged:用户可以执行的指令
- CPU怎么知道这个privileged的指令是否可以执行?
- 在CPU中增加bit,作为mode
bit,在某个mode下可以执行权限指令,某个mode下不可执行
- User Mode:Unprivileged
- Kernel Mode:Unprivileged and Privileged
- 在CPU中增加bit,作为mode
bit,在某个mode下可以执行权限指令,某个mode下不可执行
- Control Unit
- 需要侦测当前的指令是否为Privileged
- 侦测当前的mode
- RSICV的modes
- U:00,用户mode
- S:01,系统mode
- M:11,Machine mode
- R:10,Reserve
Lecture 2-1
OS Events
- 一个event是一个“unusual”change in control flow
- A usual change is some “branch” instruction within a user program for instance
- Kernel定义了许许多多的handler,用于处理不同的Event
- OS一旦启动后,一直在等待Event发生,Event发生后进行control flow的改变,使用handler
Event分类
- interrupt
- 操作系统中的,比如是keyboard
- 不同步的,可在任何阶段发生
- exceptions/trap
- 在用户和软件中的错误,比如除以0
- 同步的,执行到某行代码才知道
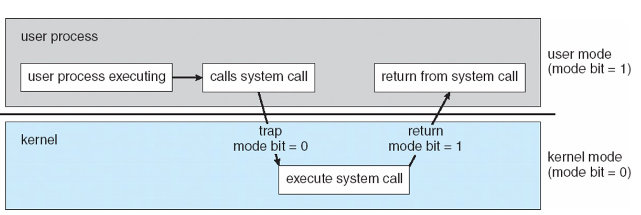
System Calls
User mode下需要硬件或者资源,那么我们需要能够进入kernel
user space和kernel之间联系的桥梁,入口点
- Arm64提供了300个syscall
System Call是一种特殊的OS Events
- 是一类Exception
Sys Call Example
- ``` mov \(0x1,\)eax syscall #arm64
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- 
#### Timers
- OS需要使用CPU,CPU有时钟周期,因此操作系统要有时钟的概念,以此区分指令对于CPU的使用率
- 使用interrupt的方法
- 每隔一定时间就发送一个Timer的Event
- Timer的handler中有一个计数器
- ```
case TIMER:
Timer.handleEvent(event);
break;
- ``` mov \(0x1,\)eax syscall #arm64
如何确定时间
- 操作系统启动只有一个启动时间
- 是相对时间:过了多少个timer interrupt
- 剩下为0,说明需要更换job
Main OS Services
Process Management
- Process is a Program in Execution
- Program:passive entity
- 没有跑起来是program
- Process:active entity
- 跑起来是process
- Program:passive entity
- OS要做:
- Creating and deleting processes
- Suspending and resuming processes
- Providing mechanisms for process synchronization
- Providing mechanisms for process communication
- Providing mechanisms for deadlock handling
- Process is a Program in Execution
Memory Management
- 操作系统的memory management决定了memory中的东西
- Kernel一直在Memory中
- OS要做
- 记录追踪谁用了多少
- 决定内存中数据的去留
- 申请和释放内存
- 操作系统的memory management决定了memory中的东西
Storage Management
IO Management
Protection and Security
OS Structures
User and Operating System Interface
用户层面
- GUI
- Batch
- Command line
- User interfaces
操作系统服务
Program Execution
- 载入运行程序
- 允许程序以多个方式结束
IO Operations
Communication
Error Detection
File Systems
Resource allocation
accounting
Protection and Security
System Calls
进入kernel的入口,program interface
- API:Application Programming Interface
- 大多数都是通过API而不是直接system call
- system call包装一下形成API
- 如printf是一个API
- write是一个system call
- printf就是把write进行了wrapper
system call:x86_64
write的过程
- call函数
- syscall,停止user的进程
- 进入Kernel mode
- Event Handler
- 返回User mode
Lecture 2-2
System Calls
- 是Kernel给UserSpace的一些功能的入口
- System Call你不会直接用,一般是warpper,即API
- 需要高效,使用数组
Sys Call的例子
- 拷贝一个文件:
- Privileged
- man命令,可以用于查询命令使用方法,可以指定查看
- 调用大量的SysCall
- strace可以给出我们调用了哪些SysCall
Sys Call的参数传递
- 通过寄存器传递,不能传递一大块内存,只能传递地址
System Service
- 系统服务,提供了更方便的software
- Ubuntu比Linux多了GUI、Software、API等
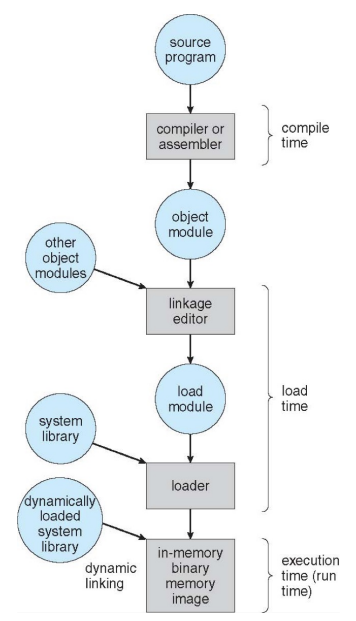
Linkers and Loaders
从高级语言到底层语言
Ø 预处理阶段
预处理器(cpp)根据以字符#开头的命令修给原始的C程序,结果得到另一个C程序,通常以.i作为文件扩展名。主要是进行文本替换、宏展开、删除注释这类简单工作。
对应的命令:linux> gcc -E hello.c hello.i
Ø 编译阶段
编译器将文本文件hello.i翻译成hello.s,包含相应的汇编语言程序
对应的命令:linux> gcc -S hello.c hello.s
Ø 汇编阶段
将.s文件翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的格式,并将结果保存在目标文件.o中(把汇编语言翻译成机器语言的过程)。
把一个源程序翻译成目标程序的工作过程分为五个阶段:词法分析;语法分析;语义检查和中间代码生成;代码优化;目标代码生成。主要是进行词法分析和语法分析,又称为源程序分析,分析过程中发现有语法错误,给出提示信息。
对应的命令:linux> gcc -c hello.c hello.o
Ø 链接阶段
此时hello程序调用了printf函数。 printf函数存在于一个名为printf.o的单独的预编译目标文件中。 链接器(ld)就负责处理把这个文件并入到hello.o程序中,结果得到hello文件,一个可执行文件。最后可执行文件加载到储存器后由系统负责执行, 函数库一般分为静态库和动态库两种。静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为.a。动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为.so,gcc在编译时默认使用动态库。
main.c通过编译器生成object文件
1 | gcc -c main.c -o main.o |
1 | cpp main.c -o main.i |
1 | gcc -S main.i -o main.o |
1 | as main.i -o main.o (二进制文件) |
- main.o通过Linkers生成可执行文件
1 | gcc -v main.o -o a.out |
- 可执行文件通过Loaders进入内存执行
Linkers
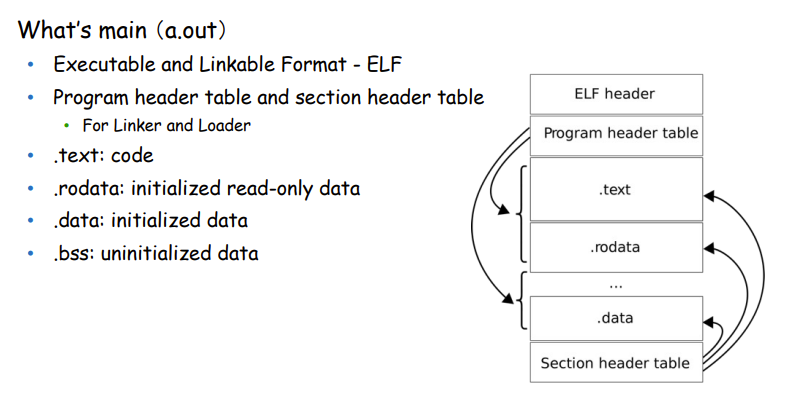
Executable and Linkable Format - ELF文件
a.out文件也是一种ELF文件
Program Header Table
- .text:code段,可读可写,可执行
- .rodata:只读数据,不可执行
- .data:初始化的data,静态变量,const
- .bss:未初始化的data
ELF文件格式提供了两种不同的视角,在汇编器和链接器看来,ELF文件是由Section Header Table描述的一系列Section的集合,而执行一个ELF文件时,在加载器(Loader)看来它是由Program Header Table描述的一系列Segment的集合
readelf
用于查看elf文件的结构
1
readelf -S a.out
Static Link
- 静态链接,所有的可执行代码,pack到一个binary中
- 可移植性强
- 大
Dynamic Link
- 动态链接
- 小,必须有动态链接库,可移植性差
- 何时被解析library call?
- loader解析的
- SysCall比较多
- 运行时动态链接是在执行程序调用到模块内容时再将动态库中的相应模块载入到内存。
Section Header Table
Loaders
- Dynamic Link的syscall比Static Link多了Dynamic Loader的syscall
Lecture 3-1
Linkers and Loaders
Loaders
- Running A Binary
- Kernel Space【高地址】
- Stack:仅仅是一段内存,没有structure
- Memory Mapping Segment:Library映射,Dynamic的libray的映射,Static没有这一段
- Heap:仅仅是一段内存,没有structure
- BSS
- Data
- Text(ELF)【低地址】
- 谁setup了ELF,把ELF进行Load到内存里?Kernel的syscall,Sys_execve (load_elf_binary)
- 谁setup了stack和heap?Kernel
- 谁setup了Library?Loader发起的
- 内核读取ELF,load到内存中,ld-xxx
Clarify
- Stack:有指针指向栈顶SP(sp寄存器)和栈底FP(通用寄存器)
- Heap:只有一个指针不在缓存里,要用时进入通用寄存器进行寻址
Static和Dynamic Link的区别
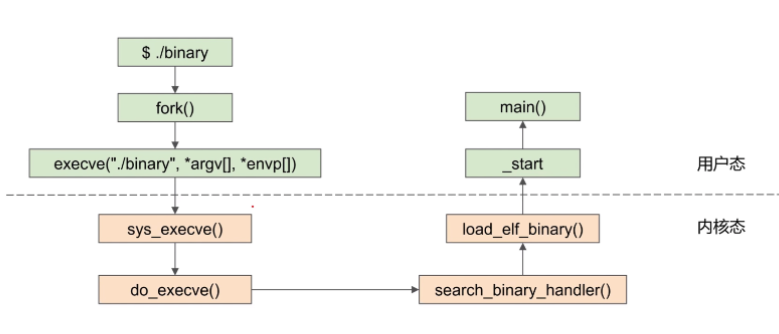
- Static
- 静态链接,所有的可执行代码,pack到一个binary中,可移植性强,大
- Entry Point Address:
- _start:c run time的一部分
- start_thread会将pc设置成entry point address作为user space的开始
- ./bin-fork()-execve-sys_execve-do_execve-search_binary_handler-load_elf_binary-_start-main()
- 在load_elf_binary函数中,会进行判断,如果是Static的,entry points会到_start
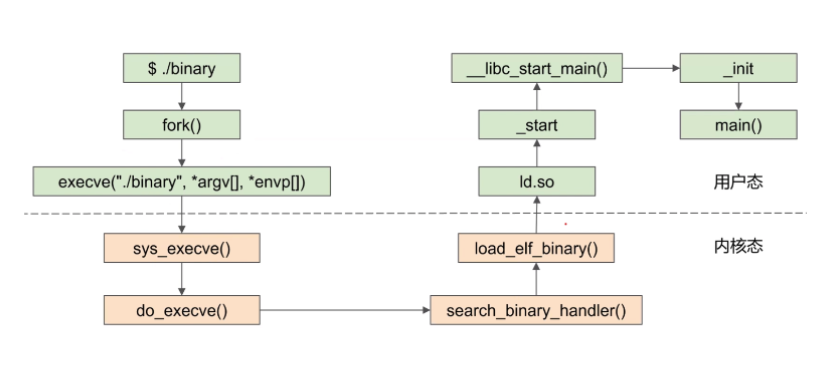
- Dynamic
- ./bin-fork()-execve-sys_execve-do_execve-search_binary_handler-load_elf_binary-ld.so-_start-__libc_start_main()-init-main()
- 在load_elf_binary函数中,会进行判断,如果是Dynamic的,entry points会到Loader
OS的设计
- User:方便、简洁、可靠、安全、快
- System Goal:好实现、灵活、可靠、有效率、error-free
- 法则:
- Policy:设计上的What will be done?
- Mechanism:实现上的How to do it?
- Door Example
- Policy:只有特定人员能进入门
- Mechanism:门禁系统
- Scheduling
- Scheduling Policy and how to pick next(mechanism)
- 早期的OS用汇编,现在用C、C++,最底层的还是用汇编实现的。
- 用高级语言容易port到hardware
- 效率问题
OS的结构
- Simple Structure:MS-DOS
- Monolithic:Unix、Linux
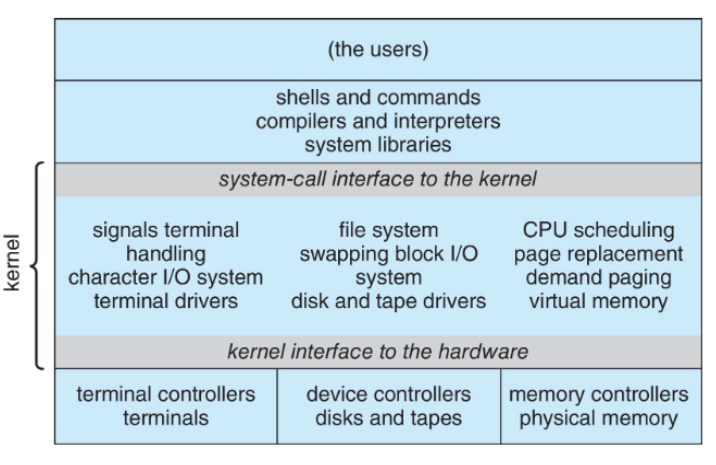
- 缺点:code全在kernel中,code多bug也多
- Layered:an abstraction
- Microkernel:Mach
- 让内核变小,将很多的代码从kernel移动到user space
- 小,好开发好移植
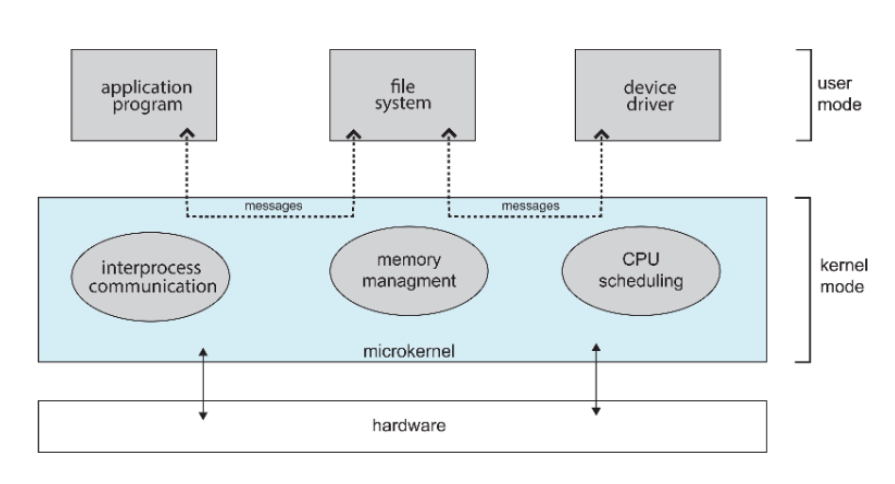
- 缺点:慢
Lecture 3-2
Processes Concept
- 进程:是一个资源组织的单元
- 进程是执行中的program
- program:passive entity
- binary被load到内存中就变成了process
- 一个program被run多次,会生成多个进程
- “job”和“process”都可以用于说明进程
- Process=
- code
- data section
- program counter【PC】
- 通用寄存器
- stack
- heap
- 用
ps au查看pid- 再用
cat \proc\pid\maps查看内存映射
- 再用
Stack
- runtime stack
- 存储临时变量,每一个调用都有一个stack,称为Stack
Frame,栈是从高地址到低地址
- x29:FP
- x30:LR
- The management of the stack is done entirely on your behalf by the compiler
- 存储临时变量,每一个调用都有一个stack,称为Stack
Frame,栈是从高地址到低地址
- function call如何返回
- 使用stack
- caller和callee保存
- Stack Frame存什么?
- 函数需要一些“state”确保他能run
- 参数
- 本地变量
- return address
- 返回值
- 方式:caller save和callee save
- 函数需要一些“state”确保他能run
- Stack不能一直向下涨,否则会overflow
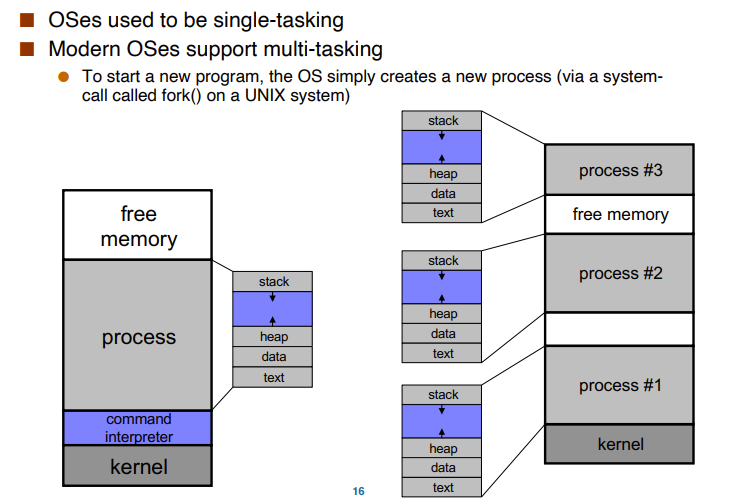
multi-Tasking
- 对于单个程序的多process,data和text是一致的即elf的内容,但是stack、heap等大小不一定
- stack和heap是不会share的
- 可执行多任务
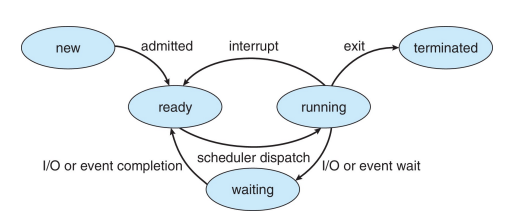
Process State
- 当一个Process执行,他会改变状态
- New:创建新的进程
- Running:指令正被执行
- Waiting:等他其他事件发生
- Ready:等待被布置在processor
- Terminated:结束
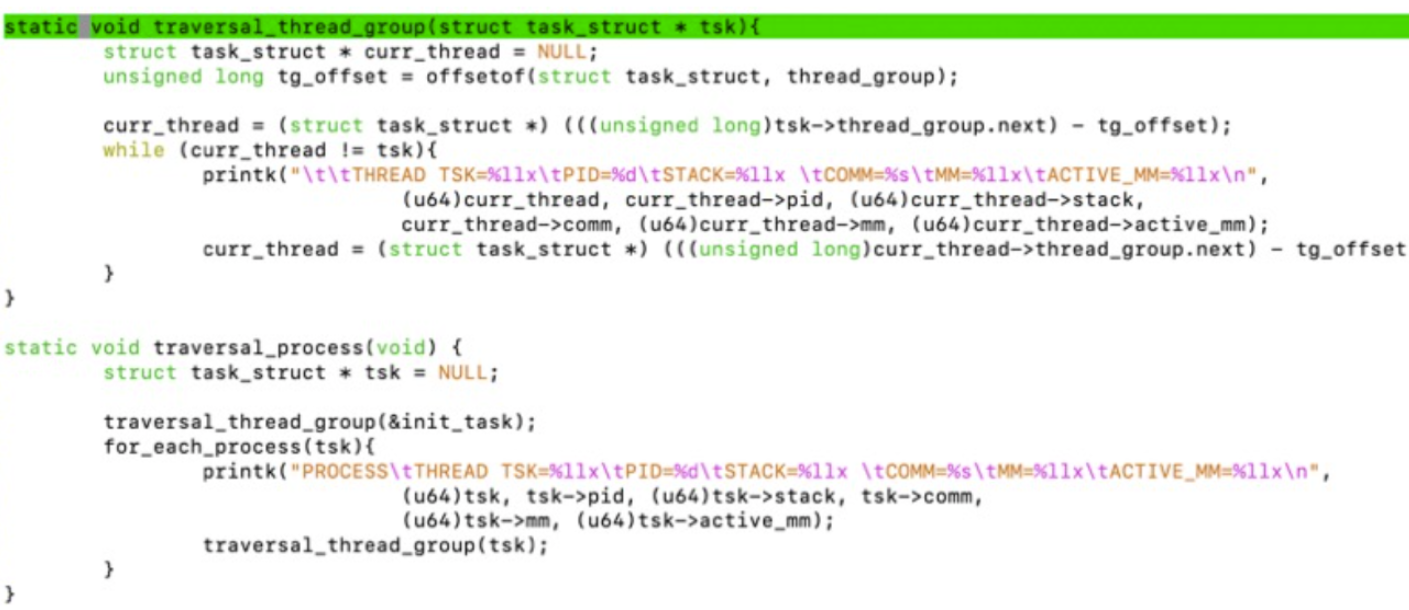
PCB(Process Control Block)
- Process的元数据
- 每一个process都有一个PCB
- Allocate当process被创建
- Free当process被结束
- 存放在数据结构task_struct中
- Process state:状态waiting,running
- Program counter:下一条要被执行的指令的位置
- CPU register:所有process-centric的寄存器
- CPU scheduling information:priorities,scheduling queue pointers进程的队列信息等
- Memory-management information:memory allocated to the process内存申请的信息
- Accounting information:CPU used,clock time elapsed since start,time limits,CPU的使用、时间
- IO status informatio:process的IO设备,打开文件的列表
【1】Process Creation
一般使用fork()的syscall
一个Process可能会创建新的process,那么就成为了parent,有了一个process tree
- 每一个process有一个pid
- child会继承、分享一些parent的资源
- parent能将input传递给child
fork()
child是一个parent的copy,但是
- pid不同
- resource utilization is set to 0
fork() return了child的pid和parent的pid
- return 两次,一次是parent进程return了子进程的pid,子进程返回了0
- 每个process可以获得本身的pid用
getpid() - 可以获得parent的pid,用
getppid()
它不需要参数并返回一个整数值。下面是fork()返回的不同值。
- 负值:创建子进程失败。
- 零:返回到新创建的子进程。
- 正值:返回父进程或调用者。该值包含新创建的子进程的进程ID
fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
- 在父进程中,fork返回新创建子进程的进程ID;
- 在子进程中,fork返回0;
- 负值,错误
【Example】
``` pid1=fork(); printf("Hello"); pid2=fork(); printf("Hello");
1
2
3
4
5
6
7
8
9
10
11
- 输出几个Hello?6个
- 【Example】
- ```
fork()
if(fork()){
fork();
}
fork()12个进程
fork()了一个process后,东西适合parent一样的,需要用execve的syscall来load一个新的program
- 因此fork和execve通常一起使用
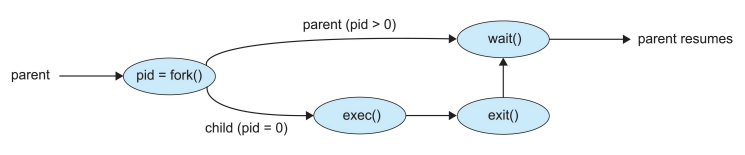
- fork搭起骨架,exec赋予灵魂
【2】Process Terminations
- 一个进程通过syscall的
exit()关闭自己- 所有的资源会被回收
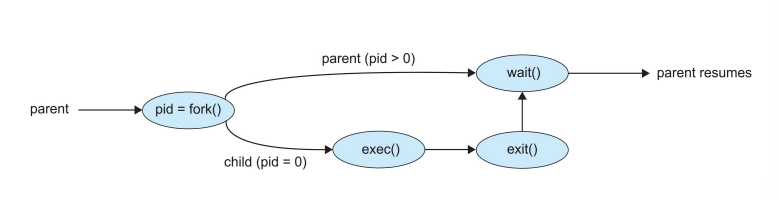
- wait()把parent进行阻止,直到child执行了exit()
- return pid of completed child and child的exit code
- waitpid()
- 阻止特定的子进程,给出pid将它wait掉
【3】Processes and Signals
- 进程可以接受信号,比如interrupt
- 信号可能有很多种发生的可能,不同的信号对应不同的操作
- 每一个信号都会造成一个进程的默认行为,可以用handler定义
- 大多数信号是不允许ignore、重载和handler的
- systemcall的signal()允许进程指定信号干的事情
- signal(SIGINT,SIG_IGN)无视
- signal(SIGINT,SIG_DEL)default操作
- signal(SIGINT,my_handler)自定义的handler
Lecture 4-1
Process State
ready和waiting的状态的process最多
running的只取决于核的多少
Process Scheduler
- 选择ready的进程作为下一个要执行的进程
- Scheduling Queues
- Ready queue:set of all processes residing in main memory, ready and waiting to execute,一般只有一个Ready Queue
- Wait queue:set of processes waiting for an event,一般有多个waiting queue,每一个对象都会有waiting queue
- 如何组织queue?使用list_head,这是在中间的,不是在头上,指向下一个list_head和前一个list_head,
*prev,*next - 有了list_head的地址,进行一个偏移,就获得了task_struct的地址
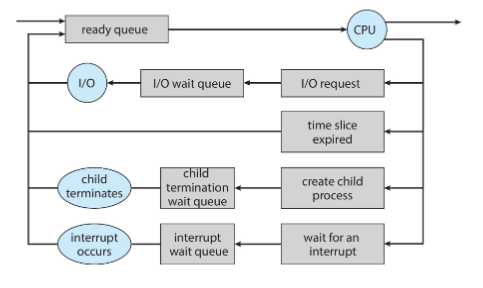
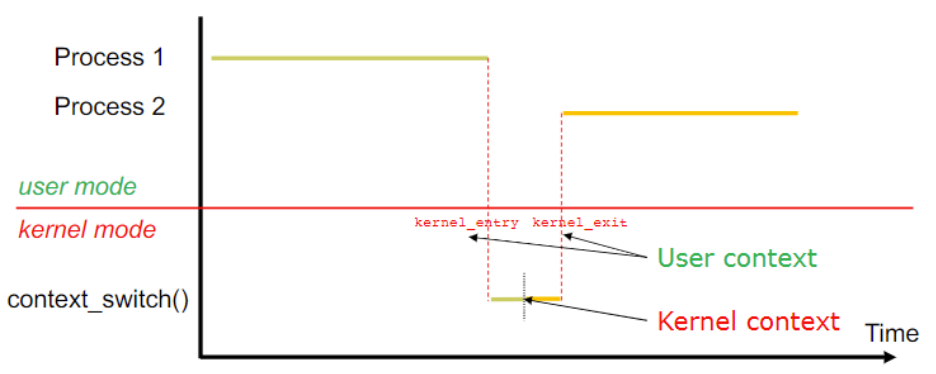
Context Switch
- 发生于CPU转换进程
- kernel做的context switch,不能让user space做,因为context switch决定了一个process用一个cpu用多久。
- 一个process在运行,来一个interrupt,需要执行一个新的进程,那么就要先save PCB0,再load state PCB1,再做save PCB1和load PCB0
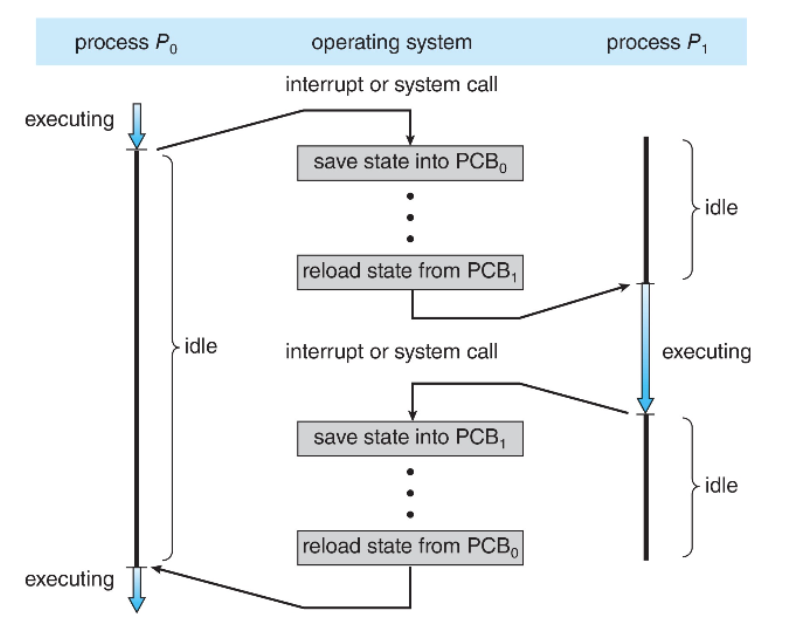
- 什么是state?
- 可以理解为context
- 不能重用的一组寄存器,需要存到内存的PCB中
- 那些硬件寄存器的值
- When CPU switches to another process, the system must save the state
of the old process and load the saved state for the new process via a
context switch
- Context of a process represented in the PCB
- Context switch time is overhead,the system does no useful work while switchin
- 一些问题
- PCB在哪个区域?
- PCB就是task_struct
- task_struct在内存里是动态分配的
- task_struct就是heap中的一个对象
- 这个切换函数如果是kernel的代码,为啥用的是ret返回(而不是特权级别的返回?
- 因为都是在kernel space做的,还没返回到user space
- reload p1 from pcb1和save p1 into
pcb1的两个pcb1是同一块内存吗,还是说reload以后原来那块pcb1就当作废弃了,之后save又选一块新的地方当作pcb1
- PCB是process的元数据,只是一部分用来放context switch的寄存器了
- PCB的生命周期是进程的生命周期
- PCB在哪个区域?
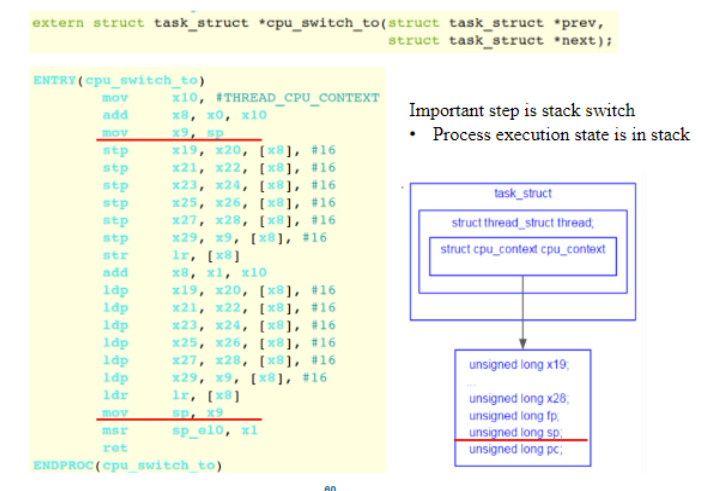
- Context switching between two kernel threads
- When and Where is the context(regs) saved?
- When:在context switch时,cpu_switch_to函数
- Where:PCB,在thread_struct
- All regs are running kernel code,termed kernel context
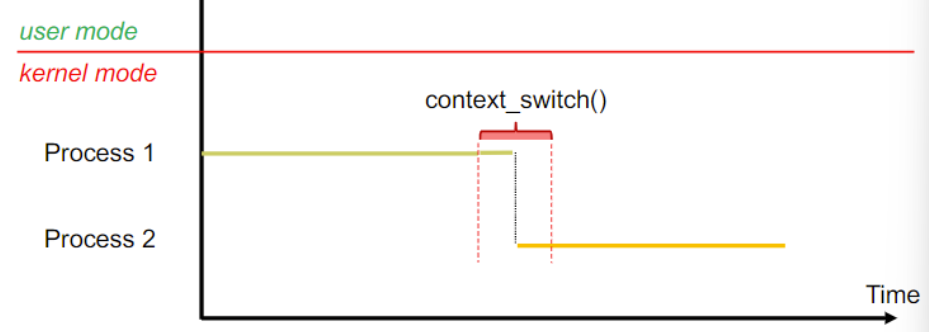
- 在user mode的context switching?
- 需要在kernel mode下switch,因此需要模式的转移
- user context regs saved?
- When:kernel_entry,kernel_exit
- Where:per-thread kernel (stack pt_regs)
- kernel context regs saved?
- When:cpu_switch_to
- Where:thread_struct
- 需要在kernel mode下switch,因此需要模式的转移
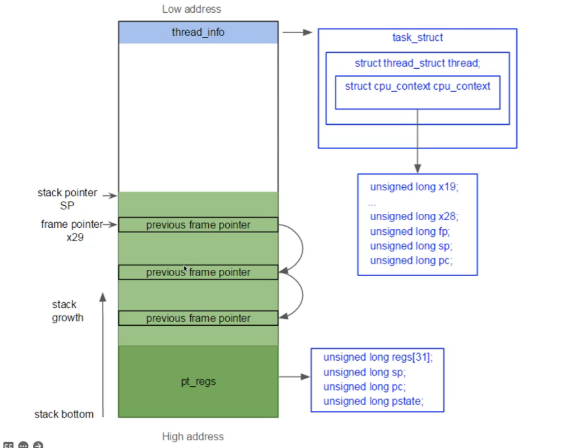
- 对于这个CPU_switch_to函数最后return到哪里去了?
- 在kernel mode中,return到p1的cpu_switch_to的caller去,即p0进去了,p1出来了,p0在下一次context switch时出来
- When the value is set?
Lecture 5-1
Fork( ) return values
- fork怎么实现的返回两次?
- Return new_pid to parent and zero to child
- 【1】返回给parent,就是一个syscall的调用,返回一个结果,这个结果就是子进程的pid。
- new_pid何时被设置?
- When:kernel_entry
- Where:pt_regs
- 先从userspace到了kernelspace,将cpu的寄存器保存在pt_regs,返回时进行reload,一般来说我们的返回值放在a0,要把new_pid放入pt_reg的a0(x0),在
ret_fast_syscall函数中进行设置
- new_pid何时被设置?
- 【Question】一个userspace的进程到另一个userspace的进程,需要几次context switch?user mode到kernel mode一次context save,进程交换一次context switch,kernel mode到user mode进行一次context save。位置分别在pt_reg和PCB
- 【2】返回给child的return是0
- child从什么时候开始run?当fork了,就ready了,进行了context switch就开始run了
copy_thread,这个函数是parent执行的函数,在这里将child的返回值设为0,即child的pt_regs中的对应值是0,当parent跑完,pc是在ret_from_fork的,当child在run时再将pt_regs的x0被设置,再用kernel_exit进行reload返回。- child执行的第一行指令是在ret_from_fork的
ret_from_fork\(\rarr\)ret_to_user\(\rarr\)kernel_exit
Zombie
- 当一个子进程terminate了,如果parent没有对它回收,那么就进入zombie状态
- The parent may still need to place a call to wait(), or a variant, to retrieve the child’s exit code
- 什么资源不能通过子进程自己释放?task_struct不能被释放,即PCB,那么就会消耗内存
- 一般来说是操作系统中的parent来释放这个PCB并且获得返回值
Getting rid of zombies
- 僵尸会逗留到:
- 它的父进程已经为子进程调用了wait()
- 或者其父进程去世
- bad practice:leave zombies unnecessarily
- 一般怎么做?
- The parent associates a handler to SIGCHLD
- The handler calls wait()
- This way all children deaths are “acknowledged”
- See nozombie_example.c
Orphans
- An orphan process is one whose parent has died
- In this case, the orphan is “adopted” by the process with
pid1被pid为1的进程收养
- init on a Linux system
- launchd on a Mac OS X system
- Demo:orphan_example1.c
- The process with pid1 does handle child termination with a handler for SIGCHLD that calls wait (just like in the previous slide!
- Therefore, an orphan never becomes a zombie
- “Trick” to fork a process that’s completely separate from the parent
(with no future responsibilities): create a grandchild and “kill” its
parent
- Demo: orphan_example2.c
- Child becomes zombie, parent needs to handle child exit properly
Lecture 5-2
- 在user mode的memory中有内存映射,stack、heap、data、text
- PCB在kernel mode的memory,不能自己更改,task_struct有thread_info、stack、pt_regs等
IPCs:Inter-Process Communication
- 进程是相互独立的,相互不影响。但是有时候我们需要进程之间的通信,这个机制如何?
Share Memory
不同的进程共享一部分内存,效率高,适合大段数据,较复杂
特点:
1. low-overhead:初始的syscall少
1. 对于使用者而言更加方便
1. 在OS中较难实现进程需要建立 establish一个共享内存区域Share Memory Region
- 一个进程创建一个共享内存区域
- 进程能将attach这个内存共享区域到他的地址空间
进程之间相互沟通通过读写共享内存区域的方式
Example:POSIX Shared Memory
进程先创建一个共享内存区域
1
id = shmget(IPC_PRIVATE,size,IPC_R,IPC_W)
进程若想要访问这个共享内存区域,必须attach上去
1
share_memory = (char*)shmat(id,NULL,0)
现在进程能够写入共享内存区域
1
sprintf(shared_memory,"hello")
当一个进程完成了,就要detach
1
shmdt(id,IPC_RMID,NULL)
进程如何知道shared memory的ID?
- 没有一个很好的方法,可以是command-line,可以是stored in file
- id在fork前产生,因此父进程和子进程都可以知道这一块共享内存区域的id
- 可以用message passing实现id的交流
Message passing
有队列,由OS维护,维护简单
特点:
- 在交换小规模数据时,更加实用
- 在OS中易于实现
- 使用send和receive实现交流
- high-overhead:one syscall per communication operation
- 不会共享任何地址空间,内存之间的独立性仍存在
- 有两个操作
- send:发送信息
- recv:接收信息
- 进程P和Q想要交流
- 建立establish一个link在P和Q之间
- 我们不需要显式的link,只需要两个函数
- send(P,message):发送一个信息给进程P
- receive(Q,message):从Q接受一个信息
- Direct or indirect
- 进程太多,这个link就很多,可以使用一个mailbox,都向这个box发送和接受
- direct
- P和Q之间直接发送信息进行交流
- 优势
- links自动建立
- 一个link能够确定一对交流的进程
- 两个进程之间存在一个link
- link可以是单向的,通常是bi-directional的
- indirect
- 使用mailbox,每一个mailbox都有一个id
- 进程之间需要沟通的话,只需要使用同一个mailbox即可
- 优势
- 连接只用建立一次
- 一个连接可能有很多的进程
- 每一对进程可能分享若干个link即mailbox
- link may be unidirectional or bi-directional
- 同步or异步
- Blocking:synchronous,时效性
- blocking send:没收到,sender不能走
- blocking receive:sender没来,接受者不能走
- Non-Blocking:asynchronous
- Blocking:synchronous,时效性
- Buffering
- link会有一个信息队列
- 实现有三种方式
- Zero Capacity:没有信息存在队列里,发送者必须等待接受者
- Bounded Capacity:有限的长度的队列,发送者要等待,如果队列满了
- Unbounded Capacity:无限的长度队列
Pipe
- 扮演着一个管道,允许进程进行交流
Ordinary Pipes
不能被创建者之外的进程访问,例如父进程和子进程之间的交流
- Ordinary Pipes allow communication in standard producerconsumer style
- Producer writes to one end (the write-end of the pipe)
- Consumer reads from the other end (the read-end of the pipe)
- Ordinary pipes are therefore unidirectional
- Require parent-child relationship between communicating processes
- fd[0] is the read end; fd[1] is the write end
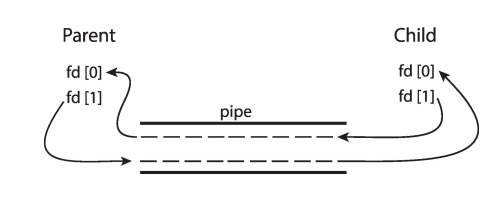
- 使用shared memory的方法,定义了0都是写,1都是读。
- Windows calls these anonymous pipes
Named Pipes
能被访问,即使没有进程之间父子关系,没有名字
ordinary的问题是只能在parent和child之前传播
- 比ordinary pipe更有力
- communication是双向的
- 不一定需要parent和child的关系
- 多个进程可以用同一个named pipe
- Provided on both UNIX and Windows systems、
实现方式就是使用一个文件(myfifo)作为中介,进程实时读写这个文件。
Client-Server Communication
Sockets、RPCs、Java RMI
Socket=ip address + port number
Lecture 6-1
Thread
Process = code + data section + program counter + registers + stack + heap,即将program进入memory进行内存映射
如何让一个process跑得更快?我们可以让一个process有多个execution units(thread)
Thread
- Thread是一个Process的基本执行单元basic unit of execution
- 每一个Thread独有的
- Thread ID
- Program Counter:执行单元因此需要PC
- Register Set:执行,需要寄存器
- Stack:不同的thread有不同的Call Path
- Shared的东西,就是Process的其他东西
- Code Section:Code不会变
- Data Section:Data是全局的变量和static的变量
- Heap动态申请内存:可以想象成多块空闲的内存串起来的,heap是统一维护的
- open File and Signals:与运行时无关
- 与执行直接相关的资源是Thread独有的
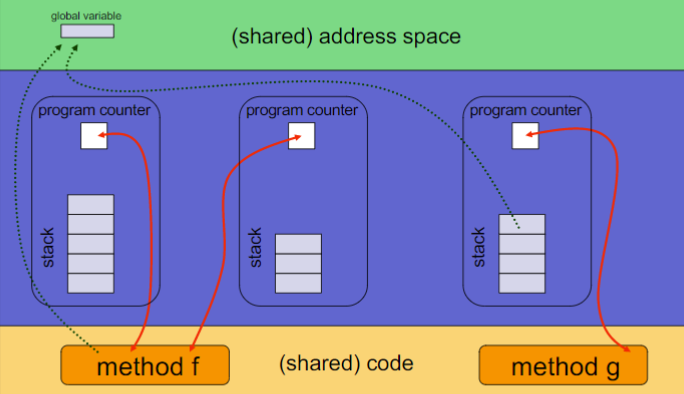
Concurrency:一个多线程的进程能做多件事在同一时间
Advantages of Thread
Economy
- Creating a thread is cheap
- 比创建进程更加cheaper
- Code,data,heap已经在内存了
- Context-Switch between threads也更加cheaper
- thread的switch不用switch那些share的东西
- Cache在switch后是hot的,不用cache flush
Resource Sharing
- 线程之间共享内存
- 不要IPC了,直接通过共享内存交流
- 在一个address space里进行并行,效率高
Responsiveness
- 反应比较快,很好的响应性
- 一个程序有并行的活动有更好的响应性
- 多个thread可以handle多个request
- 当一个thread被blocked了,其他的thread仍可以正常运行
Scalability
- 效率很高
DrawBacks
不同的thread之间,一旦一个thread出错了,整个process就挂了,就是isolation不强
不能benefit from memory protection
thread个数受到process的内存大小的限制
User Thread和Kernel Thread
- Thread可以单独支持User Space
- User Thread:执行User space的code,使用User space的stack
- Thread也可以支持Kernel Space执行
- Kernel Thread:执行Kernel Space的code,使用Kernel space的stack
- Many to one
- 一个block了就会其他的出错
- One to one
- 一个block不影响其他的,实现简单
- 资源占用率高
- m to n
- 太复杂了
Lecture 6-2
Semantics of fork() and exec()
thread的fork
- 一个thread如果call了fork,那么现在的linux是只复制这一个thread的,其实有两种选择
- 一个只有一个线程的新进程
- 一个新进程和原进程一模一样,有很多线程
- thread是通过共享数据联系的,因此当两个thread有关系,只fork了一个,是可以正常工作的,因为fork出来的是一个process,是有这些共享数据的。
Signals
大多数的Unix的版本:thread能够说出其接受和拒绝的信号
Linux:dealing with threads and signals is tricky but well understood with many tutorials on the matter and man pages
Safe Thread Cancellation
一个潜在的有用特性是线程可以直接终止另一个线程
两种可能的方法:
Asynchronous异步取消:一个线程立即终止另一个线程
Deferred延迟取消:线程定期检查它是否应该终止
可以调用线程取消请求取消一个线程,但实际取消取决于线程状态state
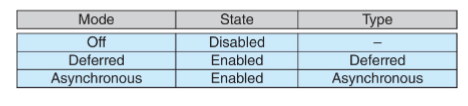
如果线程是cancellation disabled的,取消请求会挂起,直到线程的cancellation enabled
默认的Type是Deffered,thread运行到cancellation point时,cancellation才会发生
pthread_testcancel()- 然后调用清理处理程序
在Linux中,thread cancellation是通过信号解决的
Windows Threads
提供API,可以让你创建Thread
实现的是one to one的
The register set, stacks, and private storage area are known as the
context of the thread
Linux Threads
TCB:Thread的task_struct
Linux不区分PCB和TCB,一个Process有很多Thread的task_struct,哪一个才是Process的task_struct,一般来说,第一个Thread的task_struct就是整个Process的task_struct
即第一个LWP的值就是process的PID
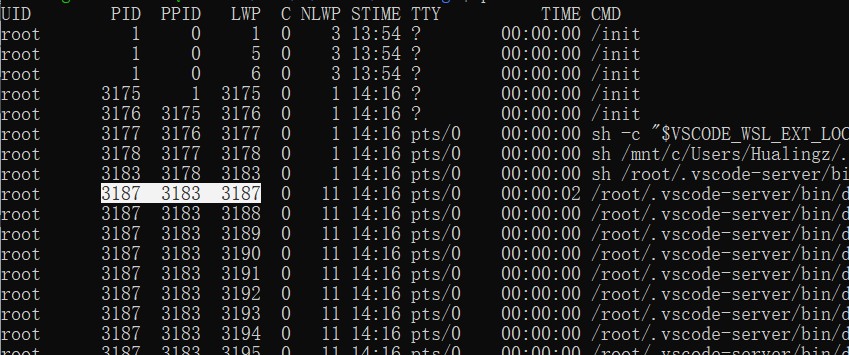
在Linux一个thread也称为LWP
syscall:clone()是创建一个thread或者一个process
fork就是调用固定参数的clone()
Linux用的task_struct既是给process的,也是给thread的。
Threads within Process
- 一个栈的大小是4KB对齐的,\(2^{12}=4K\)
- list_head
- 一般是在中间的,因此有了list head要找到task_struct的地址我们需要一个offset
User Thread to Kernel Thread Mapping
- One Task in Linux
- 有多个thread,process的task_struct来自于第一个thread的task_struct
- 一个thread,task_struct-PCB
- 用的都是User Space
- 当call了一个syscall,使用Kernel Space执行code
- task_struct只有一个放在kernel space
Lecture 7-1
CPU Scheduling
- 定义:OS决定哪个process/thread使用CPU使用多久。
- Policy是我们的scheduling strategy
- 调度者:Mechanism程序
- 被调度对象:Process
- I/O bound
- 大多数时间在等待I/O
- Many short CPU bursts
- 交互式
- CPU bound
- 大多数时间在使用CPU
- Very short I/O bursts if any
- I/O bound
- CPU bound和I/O bound谁先被调度:都可以,看OS的实现。一般来说IO优先,因为cpu时间短,且是用户交互的
- CPU-burst:
- short bursts多
- large bursts少
Scheduling方法
非抢占式non-preemptive:可以一直使用CPU到结束
抢占式preemptive:CPU可以被抢占
Scheduling的决策时机
- RUNNING到WAITING
- 等IO操作
- RUNNING到READY
- interrupt发生
- 在non-preemptive中不会发生
- WAITING到READY
- IO完成了
- RUNNING到TERMINATED
- NEW到READY
目前的OS都是Preemptive的,复杂但是有用
Scheduling的目标
- 使用率最大化CPU Utilization
- 最大化吞吐量Throughput
- 最小化周转时间Turnaround Time
- 最小化等待时间waiting time
- 最小化响应时间Response time
Scheduling Queue
- Ready和Waiting状态有队列。
- Device Queue
Dispatcher
Dispatcher模块将CPU的控制权交给调度程序选择的进程:
- switching to kernel mode
- switching context
- switching to user mode
Gantt Graph和time要会用
Scheduling Algorithm
如何挑选下一个在CPU上运行的Process?
什么是一个Good Policy?Scheduling Objective
One Thing is Certain:为了让Scheduling Algorithm能跑得更快,算法不能太复杂
First-Come,First-Served
哪个进程先来arrive,先调度
waiting time = start time - arrival time
turnaround time = finish time -arrival time
Gantt图:画时间轴
Convoy Effect:前面跑得慢的,把后面的堵住了
Shortest Job First-SJF
短的先跑,越短越优先。证明是最优的。
Non-Preemptive:
不能被抢占,在完成一个process时才会调度
Preemptive:
会被抢占,shortest-remaining-time-first,根据当前最短的时间进行调度。
现实情况下,burst time我们都不知道有多少。因此,这个算法难以使用。
我们一般要predict这个burst time,如何predict?根据Locality。
- \(\tau_{n+1}=\alpha t_n+(1-\alpha)\tau_n\)
Round-Robin轮询
轮询:每一个process都有一个时间片time quantum
跑光了就换到下一个process,FIFO的Queue。
No Starvation
wait time is bound
如何选择时间片大小?
- 短:context switch太多了整体的throughput变小,response好
- 长:throughput变大,response差
- 一般选择:10-100ms
- context-switch time:1\(\mu s\)
Priority
Priority越大优先级越高,priority can be internal和external的
存在starvation,Priority小的可能无法运行。
相同的Priority可以用轮询进行scheduling
Multilevel Queue
有多个Level的Queue,
针对不同的Queue可以每一个Queue有不同的Schedule方法
不同的Queue之间可以有Schedule方法
Multilevel Feedback Queue
一个新的process来了,放入Q0,最高优先级,使用RR(q=8)
如果它的8没用完,说明它可能是IO的,优先级要高,下次还是要来Q0
如果用完了进入Q1给q=16,用完了下次来还是Q1,否则去Q2.
......
依次类推
Lecture 7-2
Thread Scheduling
- 以Process为力度进行Scheduling,process-contention-scope,PCS
- 每一个thread都可以进行scheduling,system-contention-scope,SCS
Pthread都有两种方式的API,但是在Linux和Windows中,只能用SCS
Multiple-Processor
- Symmetric multiprocessing SMP,对称的,processor是一样重要的,每一个processor可以自行调度
- Multiple core process
- core是processor的基本计算单元
- 多个core使用一个queue
- 简单,慢,可能有锁,有竞争,效率低
- 一个core对应一个queue
- 效率高,维护多个queue,复杂
- Multi-threaded core/hyperthreading
- 一个core可以通过多线程穿插来最大化cpu使用率
OS View
- CPU1,CPU2,...,CPUn
- core 1,core2,...,corem
- 三级cache,一级二级core独享,三级共享
OS Scheduling
Windows
- 32个level的priority,数越大priority越高
- time quantum,轮询,抢占机制
- 除非是realtime的实时操作系统的一部分,否则执行完time quantum会降级
- bogus:priority=0,idle process
- idle是为了让队列里一直有可调度的process
- 手机里会跑idle但是时间不长,idle跑起来,core将会被关掉
Linux
- 数越小,优先级越高
ps -e -o uid,pid,ppid,pri,ni,cmdnice -10 ./a.out- nice值越大,thread越容易把cpu给别人
Lecture 8-1
Synchronization同步
- 现在的系统都是抢占式的
- 线程和进程是协同执行的,需要share一些内存
Data Cursh

相当于变量没来得及存入内存就又被拿来用了。
Critical Section
每一个进程都有一个Critical Section:e.g., to change common variables, update table, write file, etc.
Only one process can be in the critical section
when one process in critical section, no other may be in its critical section
each process must ask permission to enter critical section in entry section
the permission should be released in exit section
Remainder section

Critical Section Handling
- 单核CPU的Critical保护:加锁,preventing interrupts独占cpu
- Multiple-processor:interrupt难以起效果,我们加锁
- 三个Requirement
- Mutual Exclusion互斥访问
- Progress
- Bounded waiting

Peterson's Solution

P0想进去的话,flag0=true,他要看P1是不是要进去,如果p1要进去,那么p0就等待.
Peterson Solution满足三个requirement
- Mutual Exclusion:

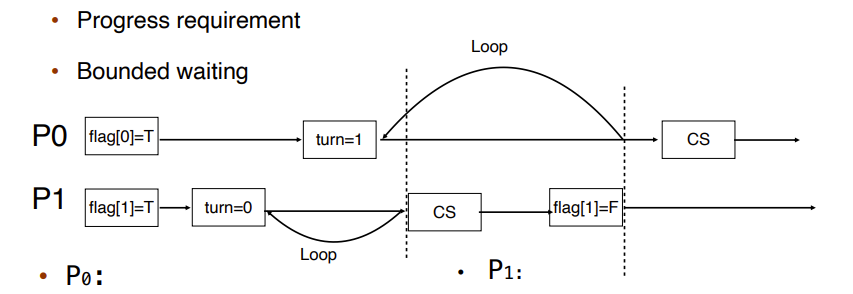
这种Solution不实用
- 只能解决两个thread的问题。
- 它假设Load和Store都是原子的。
- Instruction reorder,将指令重新排序。
Solutions:
- Memory barriers
- Hardware instruction
- Atomic variable
Memory Barriers

Weakly ordered:容易出Bug,有可能会data crash。但是容易实现。一般使用这个
Strongly ordered:难实现,一个进程对内存的修改可以马上被看到。
Hardware Instructions
- Test-and-Set Instruction
- 使用Test-and-Set的锁

- 不满足bounded-waiting
- Compare-and-Swap



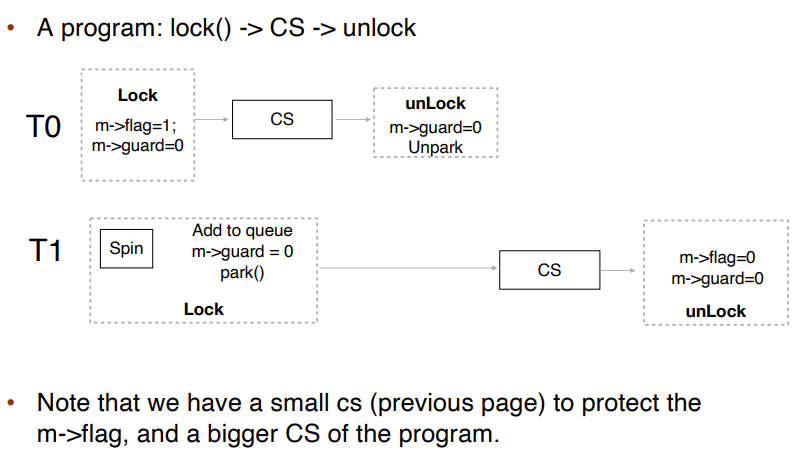
Mutex Locks

太多的Spinning Looping,因为大多数的thread都在busy waiting
Lecture 9-1
Semaphore
为了避免busy waiting
信号量:同步工具,为进程同步其活动提供更复杂的方法(比互斥锁)。
有一个数S,一般为正数。有两个操作。
wait()
- ``` wait(S){ while(S<=0) ;//busy waiting S--; }
1
2
3
4
5
6
7
- signal()
- ```
signal(S){
S++;
}
- ``` wait(S){ while(S<=0) ;//busy waiting S--; }
Counting Semaphore:计数信号量,整数值可以在不受限制的域范围内
Binary Semaphore:二进制信号量,整数值只能在0到1之间。与互斥锁相同

每一个Semaphore都有一个waiting queue,因此我们有另外两个操作
- block:阻塞,将调用操作的进程放在适当的等待队列上
- wakeup:唤醒,删除等待队列中的一个进程,并将其放入就绪队列中


- 这里的Semaphore sem;是全局的
- 其他的是对单个process做的
- 对于一个process,当期需要wait,它会被加入waiting queue,那么整个while会被block掉,不再进行,其他的process执行完critical section,signal会弹出waiting queue中的下一个要执行的process,之前那个block的process继续运行。
- 当wait时,我们需要对value进行锁的保护,在其block之前需要释放锁。


Deadlock and Starvation
死锁:两个或多个进程正在无限期地等待一个事件,而该事件只能由一个等待进程引起。

Starvation:无限期阻塞进程可能永远不会从信号量的等待队列中移除
Priority Inversion
优先级倒置:高优先级进程被低优先级任务间接抢占。
- 低优先级的任务持有锁,但由于低优先级的任务永远得不到CPU,因此永远不能完成和释放锁。
- 高优先级的任务永远等待锁
Solution:优先级继承
- 临时将等待进程(PH)的最高优先级分配给持有锁的进程(PL)
- 把低优先级的优先级提升至高优先级
Linux的Synchronization
- atomic integer
- spinlocks
- semaphores

- 在down_common中实际上已经在block之前就释放锁了。
- reader-writer locks
Condition Variable
条件变量是同步原语,它使线程能够等待特定条件发生。条件变量是不能跨进程共享的用户模式对象。

Bounded-Buffer Problem
两个进程,生产者和消费者共享n个缓冲区
- 生产者生成数据,将数据放入缓冲区
- 消费者通过从缓冲区中删除数据来使用数据。
问题是要确保:
- 如果缓冲区已满,生产者不会尝试向缓冲区中添加数据
- 消费者不会尝试从空缓冲区中删除数据,这也称为
- Producer-Consumer问题
解决方案:
- N个缓冲区,每个缓冲区可以保存一个项
- 信号量mutex互斥锁初始化为值1
- 信号量full-slots满槽初始化为值0
- 信号量empty-slots空槽初始化为值N
Producer
1 | do{ |
Consumer
1 | do{ |
Reader and Writer Problem
一个数据集在多个并发进程读取器之间共享
- reader:只读取该数据集,它们不执行任何更新
- writer:既可以读也可以写
Reader-Writer问题:
- 允许多个读取器同时读取(共享访问)share
- 只有一个写入器可以访问共享数据(独占访问)exclusive
解决方案:
- 信号量互斥锁mutex初始化为1
- 信号量写write初始化为1
- 整数读计数readcount初始化为0
Writer
1 | do{ |
Reader
1 | do{ |
Dining-Philosophers Problem
哲学家一生都在思考和吃饭
- 他们坐在一张圆桌上,但彼此不互动
只有五根筷子,他们偶尔会拿起两根筷子(一次一根)吃东西
- 哲学家问题代表了多资源同步
解决方案:
- semaphore chopstick[5] 初始化为1
当心死锁,比如所有的人拿起了一根筷子。
Lecture 9-2
DeadLock
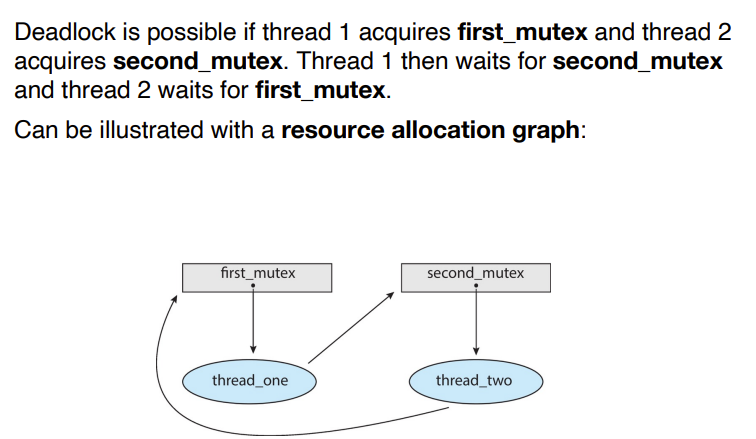
- 死锁:两个或多个进程正在无限期地等待一个事件,而该事件只能由一个等待进程引起。类似循环等待。
- 当一个死锁发生,我们可以使用back up的方法。
死锁的四个条件
- Mutual exclusion:资源互斥,一个资源一次只能被一个进程使用
- Hold and wait:持有至少一个资源的进程正在等待获得其他进程持有的额外资源
- No preemption:非抢占式,资源只能由持有它的进程在完成任务后自动释放
- Circular wait:存在一组等待进程Po, P1,…,Pn。
- Po正在等待P1持有的资源
- P1正在等待P2持有的资源
- ......
- Pn-1在等待由Pn持有的资源
- Pn正在等待Po持有的资源
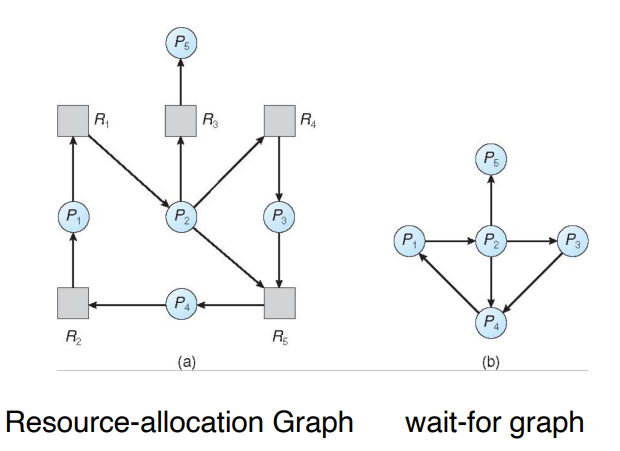
Resource-Allocation Graph
资源分配图,有两种节点:
- \(P=\{P_1,...,P_n\}\),系统中所有的进程
- \(R=\{R_1,...,R_m\}\),系统中所有的资源类型
两种边:
- request edge:\(P_i\rarr R_j\),Pi需要资源Rj
- assignment edge:\(R_j\rarr P_i\),资源Rj被Pi占用

如果图中不包含循环,则不存在死锁
如果图包含一个循环
- 如果每个资源类型只有一个实例,则死锁
- 如果每个资源类型有多个实例,则有死锁的可能
死锁的解决
- 确保系统永远不会进入死锁状态
- 预防Prevention:从四个条件入手,打破条件
- 避免Avoidance
- 允许系统进入死锁状态,然后恢复-数据库
- 死锁检测和恢复
- 忽略这个问题,假装系统中从未发生死锁
Prevention
- 如何防止互mutual exclusion
- 不需要共享资源
- 必须持有非共享资源
- 如何防止持有和等待
- 每当一个进程请求一个资源时,它并不持有任何其他资源
- 要求进程在开始执行之前请求其所有资源,只有当进程有资源时,才执行
- 只有当进程有资源时,才允许进程请求资源没有一个
- 资源利用率低;饥饿成为可能
- 每当一个进程请求一个资源时,它并不持有任何其他资源


Avoidance
使用一种算法跑一下,是否发生死锁。
Banker’s Algorithm
- allocation矩阵,资源已经分配的矩阵
- max矩阵,进程需要的资源的矩阵
- need矩阵,max-allocation
- available:不同资源的剩余量
算法:
- 找available大于need的process,那么这个process会运行完,资源被回收。
- available = available+allocation
- 一直执行,如果所有的process能被完成,那么就是safe state,不存在死锁
- 否则就存在死锁了
Deadlock Detection
画wait for graph
Deadlock Recovery
- 将process全部释放
- 一个一个释放,直到死锁没了
- 我们如何选择abort的process
- 优先级
- resource的占用量
- ......
- 我们如何选择abort的process
- Resource preemption
- 选择一个victim
- Rollback
- Starvation
Lecture 10-1
Main Memory
memory就是一块存储,里面是数据,如何理解取决于如何解释。memory就是一张白纸,我们需要管理它。
- main memory和register就是CPU能够access的储存
- memory unit能看到address + read request或者address+data+write request
- Cache在main memory和CPU register之间
- 内存需要保护
多processes需要同时在memory中运行
- fast switching
- partitioning,分块
- Protection
- Fast execution
- Fast context switch
- Loading a Process
- 重新定位相对于分区开始的所有地址
- 操作系统分配的内存保护
- 一个块一个块地到物理内存
- 一旦流程启动分区
- 不能在内存中移动
- 为什么?因为绝对地址不能变
- 一旦绝对地址变了,程序中的数据都要变
- 因此引入Logical Address
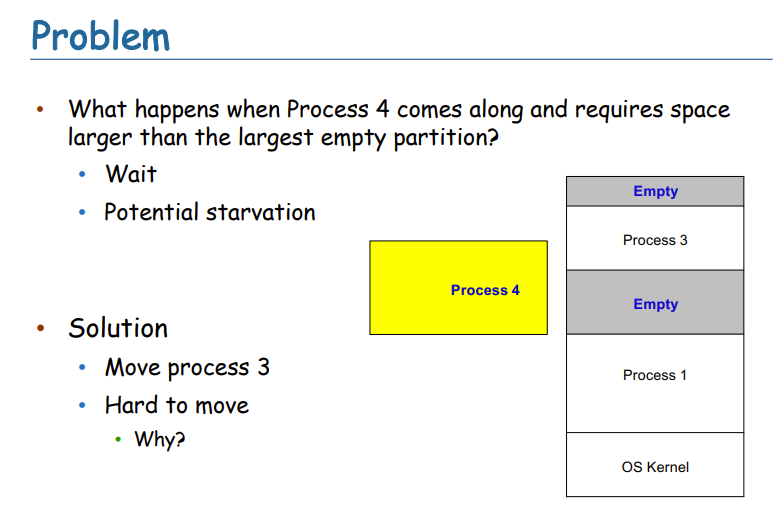
- 使用相对地址,即我们使用Logical Address

- MMU来进行地址的转换,即操作系统进行内存的映射。
Partition
每个Process看到的地址是0到max的即逻辑地址Logical Address,想要物理地址需要寻址。
有两个寄存器Base、limit
Base:process的起点
Base+limit:process的终点
保护:我们有用户看到的地址为a,那么a的物理地址是a+Base,判断这个地址是否在Base+limit以内,不能访问其他process的地址。
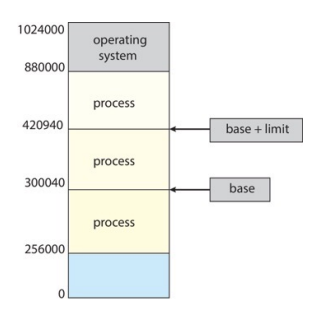
那么move的话,我们就只需要改变Base寄存器的值和复制即可
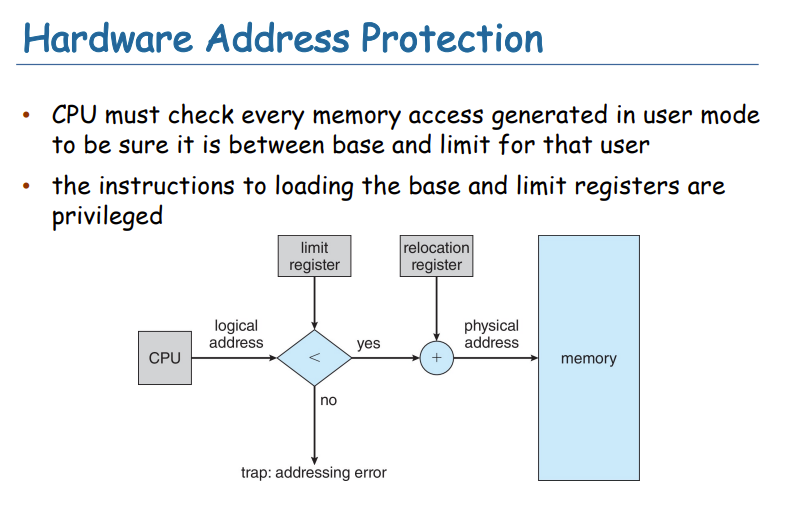
CPU使用的是Logical address
优势
- 加载时不重定位程序地址
- 所有地址都相对于零
- 限位提供内置保护
- 每个页面或块没有物理保护
- 快速执行
- 在每个指令内以硬件速度进行加法和限制检查
- 快速上下文切换
- 只需要改变base和limit寄存器
- 分区可以在任何时候挂起和移动
- 进程不知道更改
- 对于大型流程来说成本昂贵
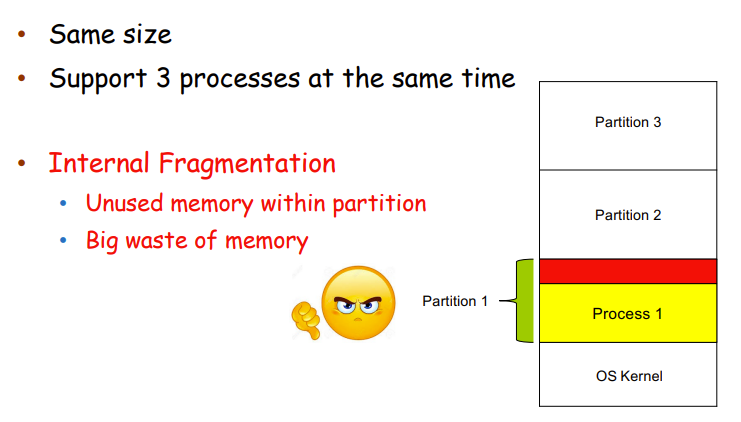
Memory Allocation Strategies
- Fixed partition:内存切分成等大小的part
- process大:用多个part
- process小:再小也要用一个
- 内部分裂Internal Fragmentation
- 分区内未使用的内存很大
- 内存浪费
- Variable partition:堆内存的切分是根据process的需要来的
- 没有internal fragmentation
- 但是有external fragmentation
- 已分配内存块之间的不可用内存总可用内存空间大于一个请求,由于空闲内存不是连续的,因此请求不能被满足
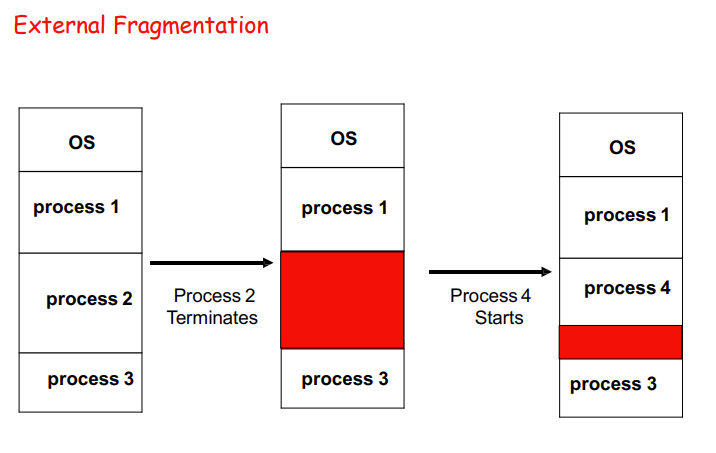
- 如何从空闲内存块列表中满足大小为n的请求?
- First-Fit:从第一个足够大的块进行分配
- Best-Fit:从足够大的最小块进行分配
- Worst-Fit:从最大的块分配
Segmentation
Partition的一种方法。
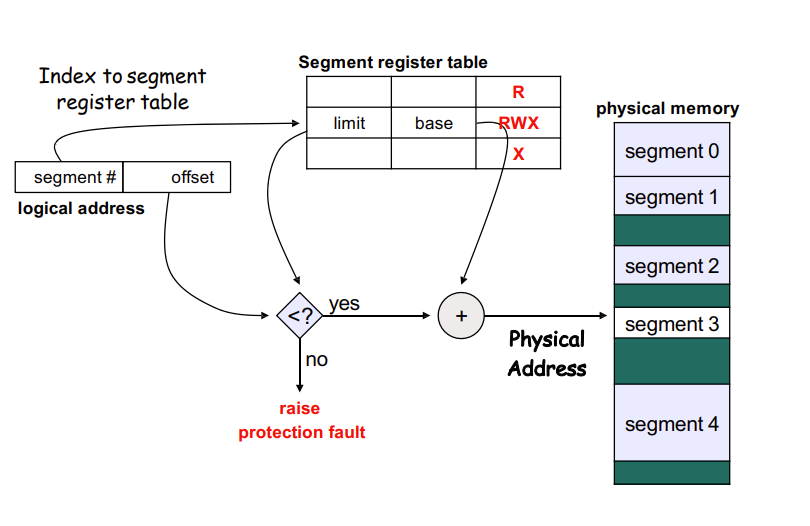
将一个program分成多个segment
process有一个segment table(in memory),有一个reg指向它,reg的内容是segment id + offset
segment id从segment table中倒找limit和base,base+offset就是Physical Address
Address Binding
地址在不同的时期呈现不同的表示
- source code:symbolic
- complier:relocatable addresses
- linker:absolute address
Logical vs Physical Address
Logical Address是我们人为规定的地址,其格式是可以人为定义的。
绑定到单独物理地址空间的逻辑地址空间的概念是正确的内存管理的核心。
- 逻辑地址——由CPU生成,也称为虚拟地址
- 物理地址——内存单元看到的地址
逻辑地址和物理地址在编译时和加载时地址绑定方案中是相同的。逻辑(虚拟)地址和物理地址在执行时地址绑定方案中是不同的。
- 逻辑地址空间是程序生成的所有逻辑地址的集合
- 物理地址空间是程序生成的所有物理地址的集合
MMU
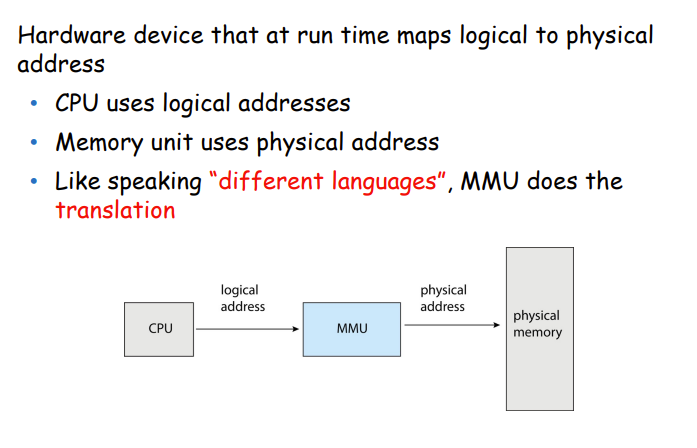

Paging分页
我们想把一个process给切分了放在memory里
[分段和分页的区别][https://geek-docs.com/operating-system/os-ask-answer/the-difference-between-pagination-and-segmentation.html]
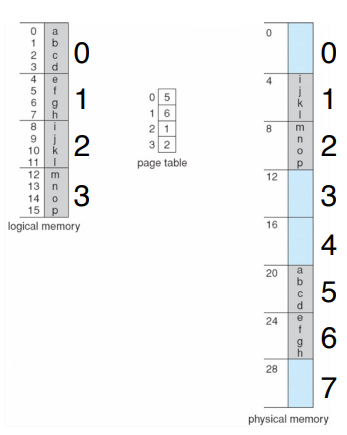
我们把physical address空间分成固定大小的块,叫做frames
- 通常是4K大小
把logical address分成块,叫做pages。即把process给分割了。
page要映射到frames上去,通过page table,将逻辑地址转换为物理地址。
- 不会有external fragmentation
- internal fragmentation很小
Page Table
储存logical page到physical frame的映射
- Example:
- 简单的page table
逻辑地址我们可以如下表示
1 | VA = | page number | page offset | |
page number:你是哪个page的
page offset:你是这个page中哪个位置的,4K的page,我们用12位就可以表示
页面转换的过程
根据page number从page table中找physical frame
physical frame+page offset就是物理地址
硬件实现
Page Table放在内存里,我们需要寄存器存放page table的基地址,在riscv中是SATP。
每一个Process有一个自己的page table,因此做context switch时,需要save这个satp。
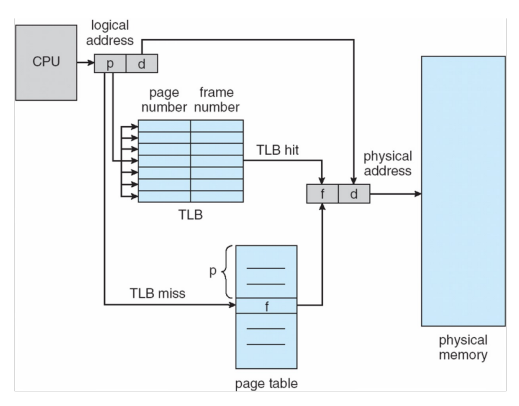
TLB
Translation look-aside buffer caches the address translation
存储一些PTE,以便后续使用
- if page number is in the TLB, no need to access the page table
- if page number is not in the TLB, need to replace one TLB entry
- TLB usually use a fast-lookup hardware cache called associative memory
- TLB is usually small, 64 to 1024 entries
Use with page table
- TLB contains a few page table entries
- Check whether page number is in TLB
- If -> frame number is available and used
- If not -> TLB miss. access page table and then fetch into TLB
在context switch时,因为我们要防止process访问其他process的frame
- Option 1:TLB中的entry全部flush掉。不好0。
- Option 2:TLB中只flush这个process的。
TLB的效率

Memory Protection
使用保护位
- 每一个page都有一个present(valid)位,表示:page已经映射到物理frame了,能被access
- kernel/user、read/write、execution、kernel-execution
- 保护位加在PTE中。
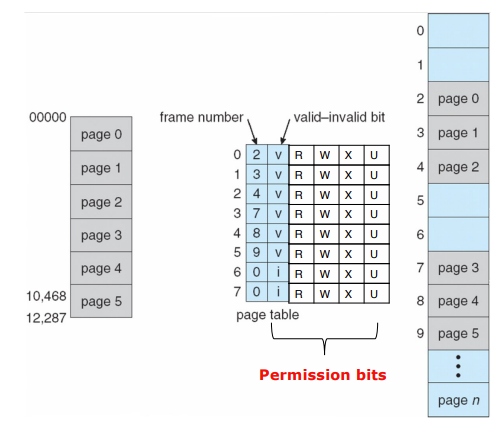
Page Sharing
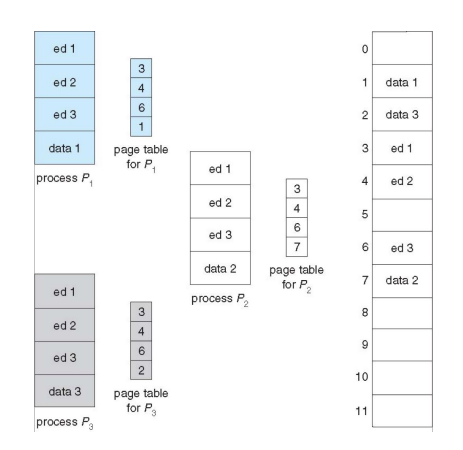
运行两个相同的process,text段是一致的,我们想省点内存。如图,ed1、ed2、ed3是共享的,物理内存是一致的。
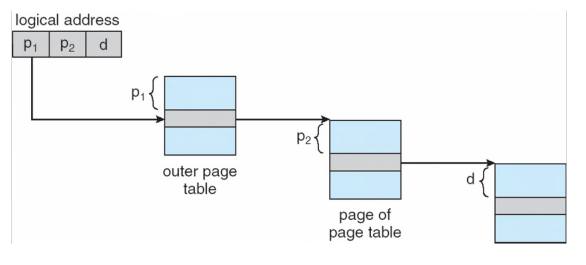
Structure of Page Table
一级页表消耗了很多的内存。
- 32bit的逻辑地址空间,4KB的page size
- entry 个数:\(2^{(32-12)}=1M\)的entry
- 每一个entry长度4Byte,页表一共占用了4MB的内存
- 要求物理连续
为了减少内存消耗,有很多方法:
- hierarchical page table 多级页表
- hashed page table
因此我们选择使用多级页表
1M个entry需要1K个page(4K)来放,一个page可以放1K个entry。
有1K个Page,因此是10+10+12
如何寻址:
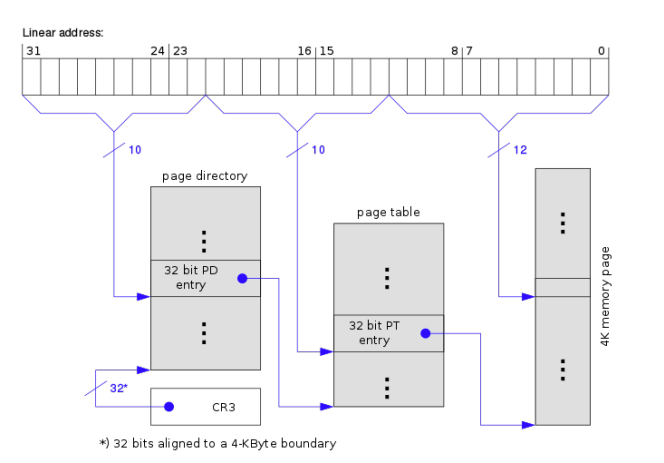
内存占用:
- 一级页表:1个Page
- 二级页表:按照实际的情况1Page~1Kpage不等
EG:64bit时,使用39位逻辑地址
- 一个entry是64bit,8byte
- 一个Page 4KB
- 一个Page装512=2^9个entry
- \(2^{39-12} = 2^{27}\)个entry
- 需要\(2^{18}\)个page
- 有\(2^{18}\)个三级页表,相当于二级页表要index这么多个entry
- 有\(2^9\)个二级页表
- 有1个一级页表
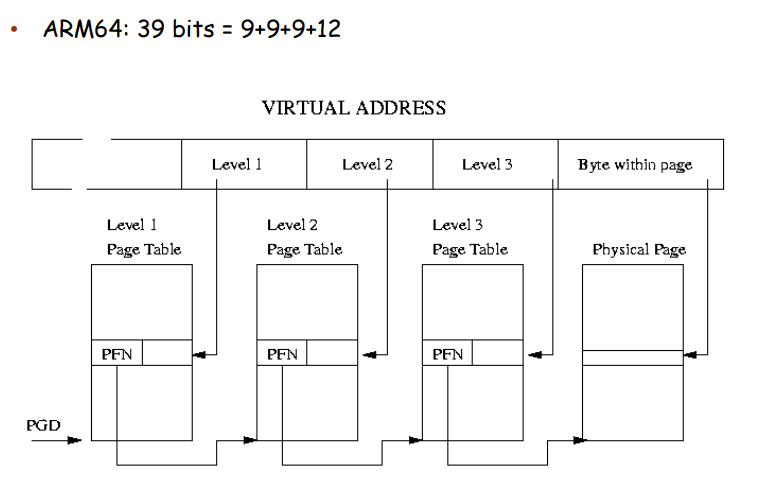
多级页表的TLB
以9+9+9+12为例,一级页表可以index 1GB,二级页表可以index 2MB,三级页表可以index 4KB,因此我们需要TLB在三级也表上更多,一级更少。
Lecture 10-2
Inverted Page Table
使用物理内存映射虚拟内存
Inverted page table tracks allocation of physical frame to a process
- one entry for each physical frame ➔ fixed amount of memory for page table
- each entry has the process id and the page# (virtual address)
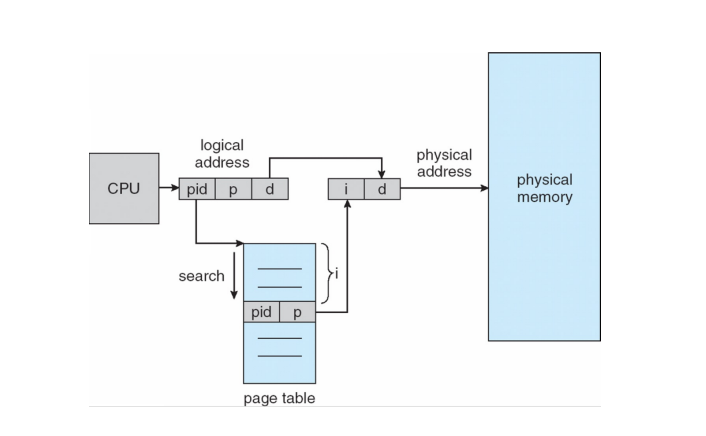
- 需要遍历查找对应pid和page num,这开销很大
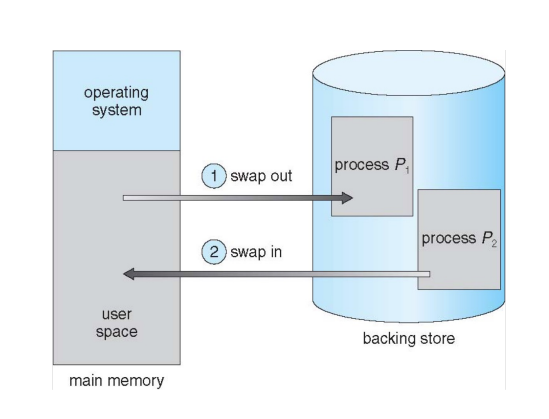
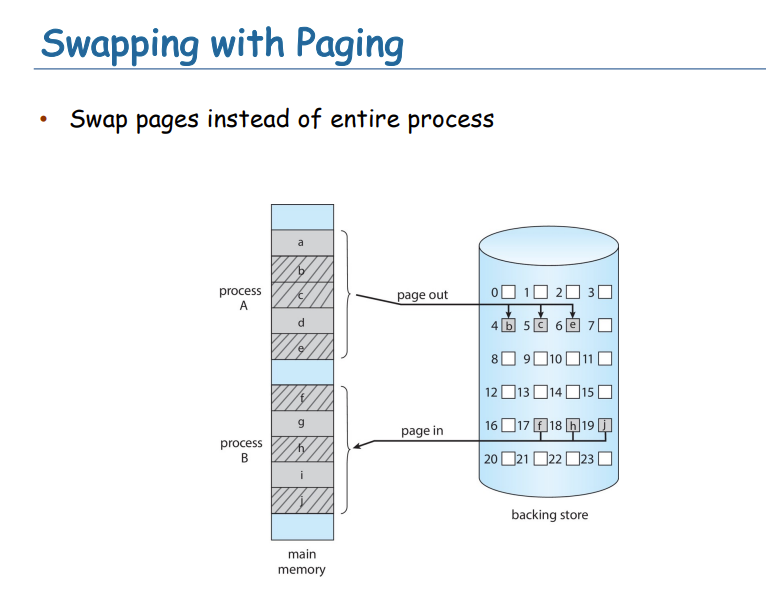
Swapping
- 使用physical的存储,来代替内存。
- 交换磁盘通过备份磁盘扩展物理内存进程
- 可以临时从内存中交换到后备存储
- 后备存储通常是一个(快速)磁盘
- 进程将被带回内存中继续执行进程
- 是否需要交换回相同的物理地址?
- 可以临时从内存中交换到后备存储
- 交换通常只在内存压力下启动由于交换
- 上下文切换时间可能变得非常长
- 如果下一个要运行的进程不在内存中,需要交换它在
- 磁盘I/O有很高的延迟
Page和Segmentation
- 目的都是为了隔离。
- https://blog.csdn.net/zhongyangtony/article/details/80879425
PAE

Linux

Lecture 11-1
Page Size变大了:Internal fragmentation变大, 访问更迅速。
- Page Size 64KB
- 64-bit,39bitVA
- offset:\(2^{16}=64K\),16位
- 一个Page多少个entry?
- \(64KB/64bit=8K=2^{13}\),13位
- 多少个Page?
- \(2^{39-16}=2^{23}\)个entry
- \(2^{23}/2^{13}=2^{10}\)个Page
- 10位
- 10+13+16
- Page Size 64KB
- 64-bit,48VA
- offset:16位
- 一个Page有\(2^{13}\)个entry,13位
- 有\(48-16=32\)个entry,需要\(2^{32-13}=2^{19}\)个Page
- 注意到19大于13,可以将每一个page看成一个entry,再加一级页表,13位
- 最后的是6位
- 6+13+13+16
Linux and Virtual Memory
Flat Memory
- 古老和现代,但简单的系统有一个单一地址空间
- 内存和外设共享
- 内存将被映射到一个部件
- 外设将被映射到另一个外设
- 所有进程和操作系统共享相同的内存空间
- 没有内存保护
- 用户空间可以使用内核
- 内存和外设共享
- 老的Memory Map是内存都已经分配好的
- Portable C programs expect flat memory
- Accessing memory by segments limits portability
- Management is tricky
- Partition
- No Protection
- Portable C programs expect flat memory
Virtual Memory
- 虚拟地址(逻辑地址)是一种地址映射
- 将虚拟地址映射到物理地址空间上去
- 映射虚拟地址到物理RAM
- 映射虚拟内存到硬件设备
- 优势:
- 每一个Process有不同的memory mapping
- 一个进程不会被别的进程看到RAM
- Kernel和User的内存也不会共享
- Memory can be moved
- Memory can be swapped to disk
- 硬件设备的memory能被映射到process的地址空间
- 硬件设备的memory能被多个process共享
- shared memory、shared libraries
- 每一个Process有不同的memory mapping
- 两个地址
- 物理地址
- 有真正的存储,硬件Memory、Hardware看到的地址是物理地址
- 虚拟地址
- 没有真正的存储,CPU看到的都是虚拟地址。
- Mapping是硬件做的:MMU
- 物理地址
MMU
MMU是用来转换虚拟地址到物理地址的,即做映射。
- 坐落在CPU和Memory之间
- Transparently handles all memory accesses from Load/Store
instructions
- 映射虚拟地址到物理地址
- Handles Permissions
- 访问错误的地址,会有一个exception:Page Fault
TLB
TLB是MMU的一部分,MMU做地址转换前需要询问TLB。
- TLB类似于一个Cache
Page Fault
A page fault is a CPU exception, generated when software attempts to use an invalid virtual address. There are three cases:
- 虚拟地址没有映射,即V值为1
- 进程对请求的地址没有足够的权限。
- 虚拟地址是有效的,但swapped了(这是一个软件条件)
Lazy Allocation
The kernel uses lazy allocation of physical memory
- 当memory被用户程序请求,物理地址不会被申请,直到it is touched
- 只是加了一下数,这个程序allocate了一定的内存
- 真正用内存时,才会真的allocate这些内存
- 这是一种优化,因为用户的程序申请的内存往往比使用的要大。
Linux-Virtual Addresses
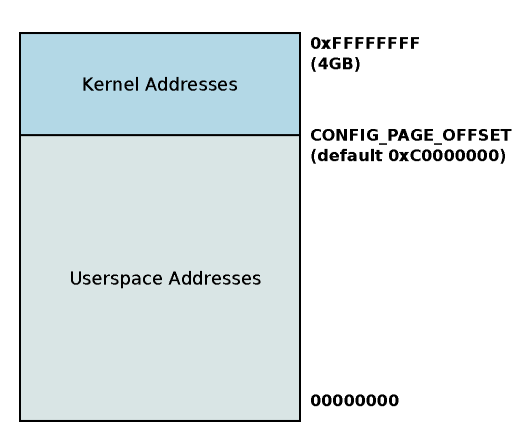
- 在Linux中kernel和user都是用虚拟地址
- 高地址部分是kernel,低地址是user
- 划分处是0xC0000000
- 32bit时是1G的kernel和3G的user
- 为什么是4G的内存?
- \(2^{32}\)个地址
- 每个地址中存放一个Byte
- 一共是4GB
- 每一个Process将会有一个独立的对user virtual address映射
- 这个mapping也要在context switch中交换
- 在64bit中的内存划分?
- 前缀FFFF的是Kernel,前缀是0000的是User
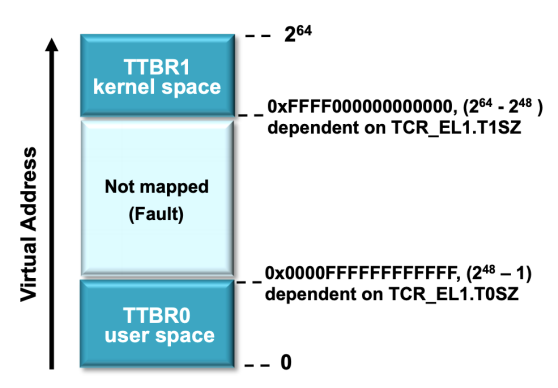
- Arm 64
- 39 bit page table
- 3 level:9+9+9+12
- 那就是64位的前25位为0时,user
- 64位的前25位为1时,kernel

Virtual address and physical RAM mapping
- Kernel如何管理物理RAM?[为什么要映射所有的物理内存][https://www.zhihu.com/question/321040802]
- 必须将RAM映射到Kernel的地址空间
- Must have an address in kernel AS
- 对于32bit的kernel的地址空间是1G的
- 32位架构下,kernel space只有1G
- 可以handle小的RAM≤896MB
- 那么如果物理内存大于kernel space怎么办?
- 我们先把896MB映射到kernel里面,剩下了128MB
- 这128MB是暂时的共享的映射
- Kernel Logical Address
- 通过线性映射物理内存使用PAGE_OFFSET
- First 896MB的Kernel AS
- 先线性映射896MB,想要转换只用加减PAGE_OFFSET
- 使得虚拟地址和物理地址的转化更方便
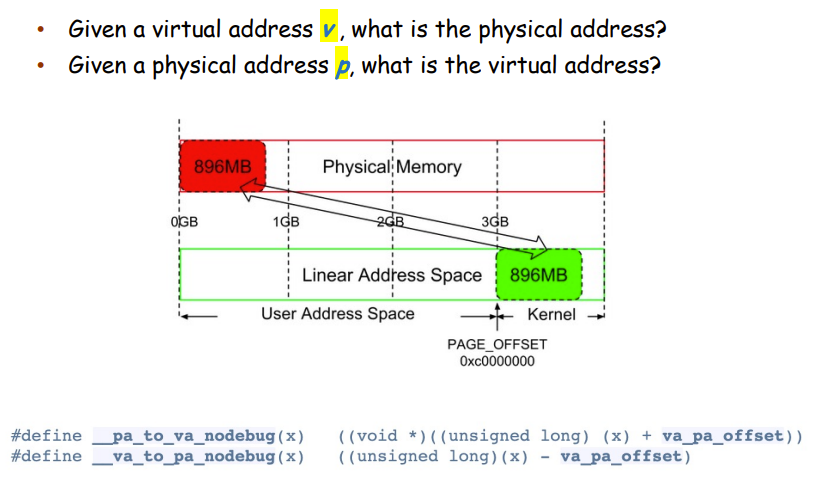
- 32位中,如果物理内存大于1G:
- 不是所有的物理内存都Linear Map,只Linear Map了896MB,剩下的128MB用来暂时映射
- 即低位【Low Memory】是Linear Map
- 高位【High Memory】是想要用时对物理地址进行Map,使用完毕就清除掉。
- High Memory找物理地址可以使用Walk Page Table即可
- Low Memory可以使用OFFSET也可以使用Page Table
- 39-bit Kernel AS
- kernel address space
- \(2^{39}*1byte=512GB\)
- kernel address space
- 48-bit Kernel AS
- kernel address space
- \(2^{48}*1byte=256TB\)
- kernel address space
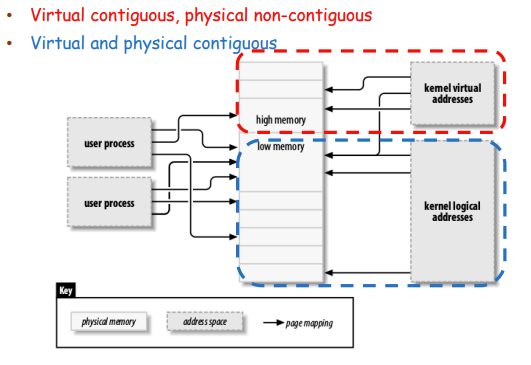
User Virtual Address
是乱序的,必须走Page Table
Kernel Virtual Address
是乱序的,必须走Page Table
Kernel Logicl Address
使用PAGE_OFFSET,也可以使用Page Table
Share Memory
Process 1和Process 2的虚拟地址可以映射到同一个物理地址上。
Lecture 11-2
Page Fault
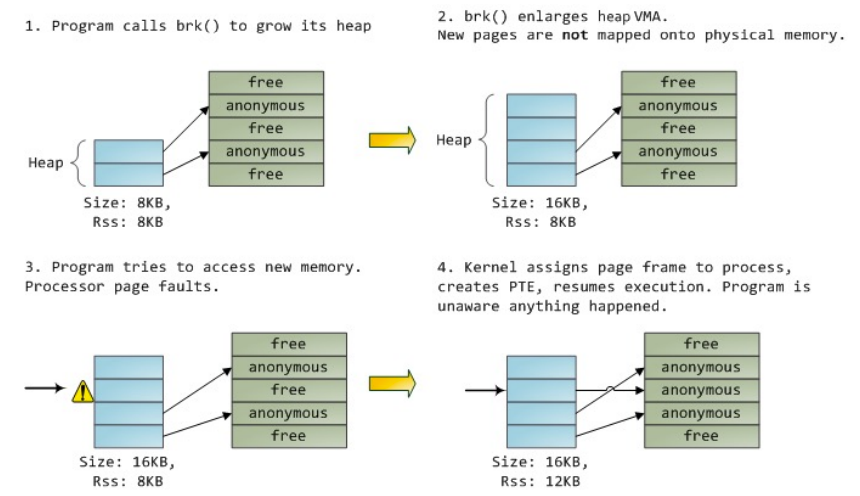
- 程序需要内存时,增大内存的虚拟地址空间,但是新的Page没有映射到物理地址
- 程序访问了新的内存,会有Page Fault
- kernel给page一个frame对应,增加页表中的项,这个新的page映射到内存上
Swapping
- 当内存分配较高时,内核可能会将一些帧交换到磁盘以释放RAM。
- 拥有一个MMU使这成为可能。
- 内核可以将一个帧复制到磁盘并删除它的TLB项。
- 该框架可以被另一个进程重用。
过程:
- 当帧再次被需要时,CPU将产生一个页面错误(因为地址不在TLB中)
- 然后,在页面出错时,内核可以
- 让流程休眠
- 从磁盘复制帧到RAM中
- 未使用的帧修复页表条目
- 唤醒进程
Demanding Paging
代码需要load到内存里才能成为进程
由于Lazy Allocate机制,可能一开始的Frame一个都没有
- 一开始就出现Page Fault
- 有了Page Fault就映射一个物理地址,即Load Frame
Partially Load
- 使用Page实现内存的分次加载,需要哪些Page,Load哪些Page,不用一次性全部Load进来
- 创建一个Process,我们需要Page Table,VMA Structure
Shared Library
- 就是一块物理内存,被映射到虚拟地址
Demand Paging就是之前说的Page Fault机制
- 就是Page需要的时候,才会有物理Frame Load进来
- mapping for new pages
- swapping for swapped pages
- 没有不必要的IO,更少的内存需求,响应速度慢,更多apps。
Page Fault Handling流程
- 需要Load M时,发现Page Table里是Invalid的
- 操作系统介入,从存储里找到Page,Load进入内存
- 重写Page Table
- 重新执行指令
Lazy Swapping
never swaps a page in memory unless it will be needed
the swapper that deals with pages is also caller a pager
Pre-Paging
总体过程
Trap操作系统
保存user寄存器和process state
A到kernel,进行一次context switch,进入kernel
查看interrupt是不是Page Fault
调用Page Fault Handler
检查Page的引用是合法的,找到Page在Disk中的位置
从磁盘读取到空闲帧
- 在队列中等待该设备,直到对读请求进行服务
- 等待设备寻道和/或延迟时间
- 开始将页面转移到一个空闲帧
在等待时,将CPU分配给其他用户
context switch到其他process上
从磁盘I/O子系统接收中断(I/O完成)
disk发出一个interrupt
为其他用户保存寄存器和进程状态
确定中断来自磁盘
更正页表和其他表,以显示页现在在内存中
等待重新为该进程分配CPU
恢复用户寄存器、进程状态和新页表,然后恢复中断的指令
context switch之前的process继续执行
Demand Paging EAT
- 假设page fault的概率:p
- \((1-p)*memory\ access+p*page\ fault\ service\ time\)
- \((1-p)*memory\ access+p*(page\ fault\ overhead+swap\ page\ out/in+instruction\ restart\ overhead)\)
- page越大,page fault的概率越小,EAT越小
Demanding Pagin和Page Fault的关系
- Demanding Paging是一个机制,Page Fault是其实现方式。
哪个硬件发出了Page Fault:MMU,MMU要执行这个Page的操作,会出现Fault
哪个硬件造成了Page Fault:User space program accesses an address
哪个硬件handle了Page Fault:OS的kernel,操作系统处理Page Fault
Copy on Write
- Copy-on-Write,加入我们需要fork,我们不想讲一模一样的page拷贝一份,此时我们可以将页表映射到同一个Frame
- 但是当一个process要写时,那么我们就copy一份再写。
- 就是要写的时候进行copy。
There is no Free Frame
memory中满了,我们需要从memory中拿Frame踢出,再从disk载入
Page Replacement
- 系统run out of memory,memory满了
- 我们选一个victim page,将其写到disk上
- 将新的page frame映射进来
Lecture 12
Get Free Frame
出现了PageFault时,我们需要拿出一个Free Frame来映射新的地址。我们要维护Free Frame,我们用一个list来维护。
There is no Free Frame
memory中满了,我们需要从memory中拿Frame踢出,再从disk载入
Page Replacement
- 系统run out of memory,memory满了
- 我们选一个victim page,将其写到disk上
- 将新的page frame映射进来
内存是一种重要的资源,系统可能会出现内存不足的情况。
- 为了防止内存不足,可以换出一些页面页面替换
- 通常是页面故障处理程序的一部分
- 选择受害页面的策略需要精心设计
- 需要减少开销,避免thrashing
- 使用修改的dirty位来减少换出的页数
- 只将修改的页写入磁盘选择一些要终止的进程(最后手段)
- 页面替换完成了逻辑内存和物理内存之间的分离—大的虚拟内存可以在较小的虚拟内存上提供物理内存
FIFO
先进先出法则:换出的都是Frames中最早进入的Frame
Page Fault比较大。
Optimal
最优法则:替换将来最长时间不使用的页面
- 9-page-fault对于上一张幻灯片的示例是最优的
- 找Frames中之后最久不用的
- 但是一般情况下我们不知道哪个Frame是最长时间不用的,无法实现
LRU
LRU:换出最长时间没有用过的
- 每一次使用Frame要更新这个Frame的时间
- 真正情况下怎么实现?
- counter-base
- 每个页表条目PTE都有一个计数器
- 每一次的page被使用,我们将clock拷贝到counter中,需要替换时,从counter中找时间戳最小的,即最长久没有用的,将其替换
- stack-base
- 使用一个栈,使用了栈中的元素,该元素移动到栈顶。
- 近似实现:reference bit
- Second-Chance Page Replacement Algorithm
- 被ref了为1
- 换出ref为0的
- 为缓存中的所有对象增加一个“引用标志位”
- 每次对象被使用时,设置标志位为1
- 新对象加入缓存时,设置其标志位为0
- 在淘汰对象时,查看它的标志位。如果为0,则淘汰该对象;如果为1,则设置其标志位为0,重新加入队列末尾。
- 以固定的间隔重新排序比特
- 假设每个页面有8位字节在一个时间间隔(100ms)内,位权移动1位,设置高位位(如果使用),然后丢弃低位位
- 00000000 =>在8个时间间隔中没有被使用
- 11111111 =>在所有时间间隔中都被使用
- 11000100 vs 01110111:哪个最近使用的更多?11000100更多,替换01110111
- Second-Chance
- 这是FIFO算法的改进版,相对于FIFO算法立刻淘汰对象,该算法会检查待淘汰对象的引用标志位。如果对象被引用过,该对象引用位清零,重新插入队列尾部,像新的对象一样;如果该对象未被引用过,则将被淘汰。
- Enhance Second-Chance Algorithm
- 两个位

- counter-base
LFU
Counter Base的
- Least Frequently Used:最少被用的Page被换出去
- 一个页面在进程初始化期间被大量使用,然后从未使用过
- Most Frequently Used:用的最多的Page被换出去
- 根据这个论点,计数最小的页面可能刚刚被引入,还没有被使用
Page-Buffering Algorithm
- 始终保持一个空闲帧池
- 需要时可用的框架,不需要在故障时查找
- 把页面读到自由帧,而不是等待受害者写出来
- 尽快重新启动
- 在方便的时候,驱逐受害者
- 可能的话,保留修改过的页面列表
- 当磁盘空闲时,在那里写入分页并设置为非脏分页:可以在不写入分页到后备存储的情况下替换该分页
- 可能的是,保持空闲帧内容完整,并注意其中的内容——一种缓存
- 如果在重用之前再次引用,则不需要再次从磁盘加载内容
- 缓存命中
- 所有这些算法都让操作系统猜测未来的页面访问
- 有些应用程序有更好的知识——例如数据库
- 内存密集的应用程序可能导致双缓冲-浪费内存
- 操作系统将页面的副本保存在内存中作为I/O缓冲区
- 应用程序为自己的工作在内存中保留页面
- 操作系统可以直接访问磁盘,避免了应用程序的妨碍
- 裸盘模式绕过缓冲、锁定等
Frame Allocation
根据指令语义,每个进程需要最少的帧数、
用于进程内存分配的两种主要分配方案
- 平等的分配Equal
- For example, if there are 100 frames (after allocating frames for the OS) and 5 processes, give each process 20 frames
- 按比例分配Proportional
- Allocate according to the size of process
Global/Local Allocation
- 全局替换
- 进程从所有帧集合中选择一个替换帧
- 一个进程可以从另一个进程获取帧但是流程执行时间可能会有很大的差异,这取决于其他流程但更大的吞吐量
- 本地替换
- 每个进程只从自己分配的帧集合中进行选择
- 更一致的每进程性能但可能是没有充分利用内存
Page Reclaiming
实现全局页面替换策略的策略
所有的内存请求都从空闲帧列表中得到满足
当列表低于某个阈值时,将触发页面替换,而不是等待列表降为零才开始选择要替换的页面。
- 积极地回收页面
- 终止一些进程
- 根据OOM评分
- 在可用内存不足的情况下终止的可能性有多大
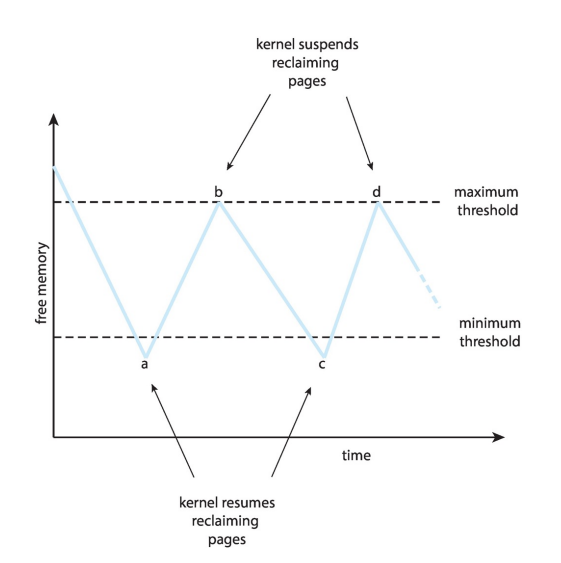
这种策略试图确保总有足够的空闲内存来满足新请求。
Major and Minor Page Fault
- Major:page is referenced but not in memory
- 需要去disk里面找Frame
- Minor:mapping does not exist, but the page is in memory
- 没有页表映射,但是Page在memory中了
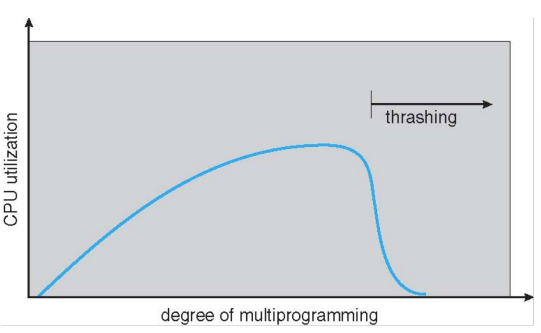
Thrashing
- 如果进程没有“足够的”页面Page Fault可能会很高
- Page Fault获取页面,替换一些现有的Frame
- 但很快需要替换的Frame回来
- 一个process一直在换进换出,导致cpu使用率低。
- 为什么需要分页工作?
- 进程内存访问具有高局部性locality
- 进程从一个局部性迁移到另一个局部性
- 为什么Thrashing发生?
- total memory size < total size of locality
- 比如说 物理内存不够,进程所访问的页都没有被加载到内存,从而导致缺页中断 需要把该页加载 而如果此时内存不够的话,却发现系统的可替换的页(从内存-> 虚拟内存)很少,这个好像是使用 最近最少使用(访问)的算法判断的吧, 这里可能就会出问题了
Working Sets Model
在单纯的分页系统里,刚启动进程时,在内存中并没有页面。在CPU试图取第一条指令时就会产生一次缺页中断,使操作系统装入含有第一条指令的页面。其他由访问全局数据和堆栈引起的缺页中断通常会紧接着发生。一段时间以后,进程需要的大部分页面都已经在内存了,进程开始在较少缺页中断的情况下运行。这个策略称为请求调页(demand paging),因为页面是在需要时被调入的,而不是预先装入。不过幸运的是,大部分进程不是这样工作的,它们都表现出了一种局部性访问行为,即在进程运行的任何阶段,它都只访问较少的一部分页面。例如,在一个多次扫描编译器中,各次扫描时只访问所有页面中的一小部分,并且是不同的部分。
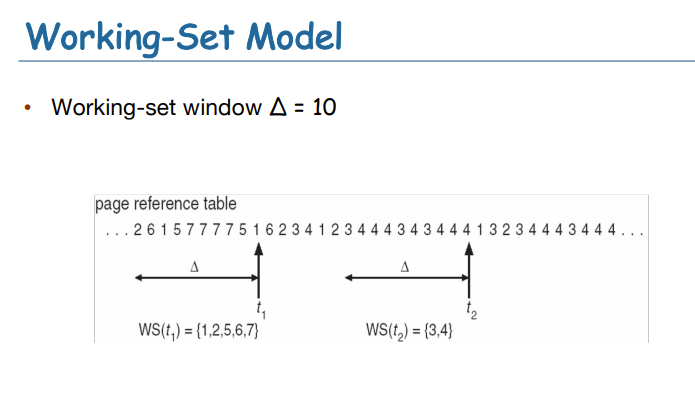
- 一个进程当前正在使用的页面的集合称为它的工作集(working set)
- working-set window一个时间窗口,working
set就是统计在这个时间窗口使用的页面的集合
- 如果时间窗小:不会include entire locality
- 如果时间窗大:会include entire locality
- 如果时间窗为无穷:将include entire program
- 进程\(p_i\)的working set:时间窗口内进程使用的页面的集合
- Total working sets:\(D=\sum
WSS_i\)
- 全部的locality的近似
- 如果\(m<D\),可能会thrashing
- Example:
- interval time + a reference bit
- 假设:时间窗\(\Delta = 10000\)
- time interrupts after every 5000 time units
- keep in memory 2 bits for each page
- 当time interrupt发生,我们把其他的reference bit设置为0
- 当内存中的bits=1,page就是在working set中
- 改进:更多的bit和更短的timer interrupt
- 假设:时间窗\(\Delta = 10000\)
- 假设没有颠簸
- 进程的工作集与其页面故障率之间的直接关系
- 工作集随着时间的推移而变化
- 随着时间的推移出现高峰和低谷
Page-Fault Frequency
- 比WSS更直接的方法
- 建立“可接受的”Page Fault Frquency(PFF)
- 如果实际速率过低,进程丢失帧
- 如果实际速率过高,进程获得帧
- 需要换出一个process,如果没有free frames可用
Lecture 13
Kernel Memory Allocation
- 内核内存分配不同于用户内存,它通常从一个空闲内存池中分配
- 为什么用Lazy Allocation?
- 节约内存资源
- "加入购物车不下单",在真正使用时才申请
- 怎么节约CPU的资源?
- 通过调度,如果需要等IO或者等内存,那么就要将CPU让出来,即context switch。
- 为了让下一个process尽快进入CPU,使用Ready Queue
- Semaphore
- busy waiting会占用cpu,引入Semaphore
- 为什么用Lazy Allocation?
- 内核为不同大小的结构请求内存
- 可以最大限度地减少由于碎片造成的浪费
- 一些内核内存需要在物理上是连续的
- 在kernel中,申请内存要一个一个Page的申请,并且需要全部用完,避免浪费
- Kernel不能使用Lazy Allocation,是立即满足内存需求的。Kernel一定要Lean&Mean,Lean就是精简,Mean就是一心一意只做一件事
Page Fault Handling in Linux
- do_page_fault
- 判断是bad area还是good area
- 就是看Page在memory中没有映射还是没有在内存中。
- 当一个program需要内存,操作系统将VMA的大小增大,当真的要去访问这个地址,出现了Page Fault,判断是good还是bad area。
Buddy System
- 为了减少碎片化,物理内存都是2的n次方。Memory Allocation使用2的幂次
- 内存以2的幂为单位分配
- 向最近的分配单位提出请求
- 将单位分成两个“伙伴”,直到有合适大小的块可用
- 比如我们假设只有256KB的块可用,内核请求21KB
- 分成A1和A2,各128KB
- 进一步将一个128KB的块分割为B1和B2的64KB
- 再分割为32KB+32KB
- ....
- 优点:它可以快速地将未使用的块合并为更大的块
- 缺点:内部碎片化
- 内存以2的幂为单位分配
Slab Allocator
- Slab分配器是一个缓存对象
- slab分配器中的cache由一个或多个slab组成
- 一个slab包含一个或多个page,这些页面被划分为大小相等的对象
- 内核为每个惟一的内核数据结构使用一个cache
- 当创建缓存时,分配一个slab,将slab划分为空闲对象
- 数据结构的对象是从slab中的自由对象中分配的
- 如果一个slab充满了用过的对象,下一个对象来自一个空的/新的slab
- 优点:无碎片(物理连续),内存分配快pool
- 一些对象字段可能是可重用的;不需要再次初始化
Prepaging
- 减少进程启动时出现的大量页面错误
- 在引用流程所需的全部或部分页面之前,将它们预先分页
- 但是如果未使用prepaging的页面,则会浪费I/O和内存
- 假设s个page被prepaged了,有α比例的page被使用了
- s(1-α)被浪费
PageSize
- 有时操作系统设计者有一个选择
- 特别是如果运行在定制的CPU上
- 页面大小的选择必须考虑
- 碎片->小页面
- 页表大小->大页面
- 分辨率->小页面
- I/O开销->大页面
- 页面错误数->大页面
- Locality ->小页面
- TLB size和有效性->大页面
- 总是2的幂,通常在\(2^{12}\)(4096字节)到\(2^{22}\)的范围内(4194304 字节)
- 平均而言,随着时间的推移而增长
TLB reach
- TLB访问范围:从TLB可访问的内存量
- \(TLB\ Reach = (TLB\ size)\times(page\ size)\)
- 理想情况下,每个进程的工作集都存储在TLB中
- 否则会出现严重的TLB缺失
- 增加页面大小以减少TLB压力
- 它可能会增加碎片,因为并非所有应用程序都需要大页面
- 多个页面大小允许需要更大页面的应用程序使用它们,而不会增加碎片
I/O interlock
- I/O互锁——页面有时必须锁在内存中
- 考虑I/O—用于从设备复制文件的页必须被锁定,不能被页替换算法选择为清除
Lecture 13-1
Memory Management Summary
- Partition
- 直接管理物理Phy memory
- 一开始只用run一个job无需担心内存分配,后来需要多个进程,要把系统内存分配
- fix len:internal
- variable len:external
- Segmentation
- Base+limit
- Logic Address
- 没有避免external fragmentation
- Paging
- 一级页表:页表本身占用空间大
- 多级页表
- demand paging
- page replacement
- working set
Mass-Storage Structure
- 永久的存储介质
- 磁盘为计算机系统提供大量的二次存储
- 硬盘是最受欢迎的;一些磁盘可以移动
- 驱动程序通过I/O总线连接到计算机(例如,USB, SCSI,EIDE,SATA...)
- 驱动器以每秒60到250次的速度旋转(7200rpm= 120rps)
- 磁盘有盘片,范围从.85"到14"(历史上)
- 3.5",2.5",和1.8"现在很常见英寸
- 每个驱动器的容量范围从30GB到3TB,甚至更大
Moving-head Magentic Disk
磁盘驱动器被编址为1维逻辑块阵列(LBA)
- 逻辑块是传输的最小单位
逻辑块按顺序映射到硬盘的扇区中
- 扇区sector 0是最外层圆柱体上第一轨道的第一扇区
- 按顺序绘制进度
- 然后是cylinder里剩下的痕迹
- 然后通过其余的cylinder从最外到最内
逻辑到物理地址应该是容易的
- 除了坏扇区
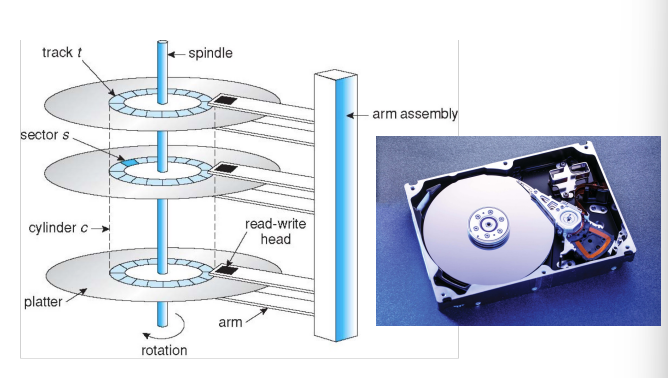
Positioning time移动磁盘臂到所需的节的时间
- positioning time includes seek time and rotational latency
- Seek time:挪动磁头,在不同道上移动
- Rotation lantency:转动磁盘,在同一个道上获取sector
- 定位时间也称为随机访问时间
- positioning time includes seek time and rotational latency
Performance
- 传输速率:理论6GB/sec;有效(真实)约1GB/sec
- 传输速率是数据在驱动器和计算机之间流动的速率
- 寻道时间从3ms到12ms(桌面驱动器常见为9ms)
- 基于主轴转速的延迟:1/rpm * 60
- rpm:rotation per minute
- 平均延迟=0.5延迟
- 传输速率:理论6GB/sec;有效(真实)约1GB/sec
Average Access Time = average seek time + average latency
- for fastest disk 3ms + 2ms = 5ms
- for slow disk 9ms + 5.56ms = 14.56ms
Average I/O time:average access time + (data to transfer / transfer rate) + controller overhead
- e.g., to transfer a 4KB block on a 7200 RPM disk; 5ms average seek time, 1Gb/sec transfer rate with a .1ms controller overhead:
- 5ms+4KB/1GB/1sec+0.1ms+4.17ms(average latency)
Disk Scheduling
Disk scheduling usually tries to minimize seek time,在cylinder之间移动
- rotational latency is difficult for OS to calculate
- 近似两个cylinder的距离,让磁头移动距离最短。
- We use a request queue of cylinders “98, 183, 37, 122, 14, 124, 65,
67” ([0, 199]), and initial head position 53 as the example
- 一共是640
SSTF:Shortest Seek Time First
- 每一次找寻道时间最短的
- 不是最优的
SCAN:电梯算法
1 | SCAN算法,也就是很形象的电梯调度算法。先按照一个方向(比如从外向内扫描),扫描的过程中依次访问要求服务的序列。当扫描到最里层的一个服务序列时反向扫描,这里要注意,假设最里层为0号磁道,最里面的一个要求服务的序列是5号,访问完5号之后,就反向了,不需要再往里扫。结合电梯过程更好理解,在电梯往下接人的时候,明知道最下面一层是没有人的,它是不会再往下走的。 |
硬盘臂从硬盘的一端开始向另一端移动
服务请求在移动期间,直到它到达另一端
然后,反转头部运动,继续服务。
优势
- 高吞吐量
- 响应时间方差低
- 平均响应时间
缺点
- 对磁盘臂刚刚访问的位置的请求等待时间过长
C-SCAN
- Circular-SCAN旨在提供更统一的等待时间
- 头部从一端移动到另一端,同时为请求提供服务
- 当头部到达末端时,它立即回到起点
- 回程时不处理任何请求
- 它本质上把圆柱体当作一个循环列表
LOOK/C-LOOK
- SCAN和C-SCAN从头到尾移动
- 即使在实现中没有I/O,头也只到最后一个请求方向
- LOOK是SCAN的一个版本,C-LOOK是C-SCAN的一个版本
磁盘调度性能取决于请求的数量和类型
- 磁盘调度应该被写成一个独立的,可替换的模块
- SSTF是常见的,是默认算法的合理选择
- LOOK和C-LOOK对于I/O负载较重的系统性能更好
- 磁盘性能会受到文件分配和元数据布局的影响
- 文件系统花费大量精力来增加空间局部性
Nonvolatile Memory Devices
- SSD,有写的寿命,需要一个较好的管理。
- 以“页”增量(考虑扇区)读取和写入,但不能就地覆盖
- 必须首先被擦除,擦除发生在更大的“块”中
- 假设块大小:64k有16页,页面大小:4k
- 一般能写100000次
- Management
- 将一个常写的文件写在不同的block上。
- 需要一个调度
- 将常写的一直挪动。
优点:
- 没有机械结构,不易损坏
- 体积小,密度高
NAND Flash Controller Algorithm
- With no overwrite, pages end up with mix of valid and invalid data
- 为了跟踪哪些逻辑块是有效的,控制器维护flash转换层(FTL)表格
- 还实现了垃圾收集以释放无效的页面空间-可用的页面,但没有空闲块
- 分配超额配置,为GC提供工作空间
- 将好的数据复制到超额配置区域,并擦除该块以备以后使用
- 每个单元格都有生命周期,因此需要对所有单元格进行平等写入
Magnetic Tape
磁带是早期的二级存储,现在主要用于备份
- 大容量:200GB ~ 1.5 TB
- 访问时间慢,特别是随机访问
- 是顺序访问
- 寻道时间比磁盘高得多
- 一旦数据在磁头下,传输速率相当于磁盘(140 MB/s)
- 需要对磁带进行随机访问
- 存储在磁带上的数据相对永久
Disk Management
- 物理格式化Physical
Formatting:将磁盘划分成扇区,供控制器读写
- 每个扇区可以保存报头信息,外加数据,外加纠错码(ECC)
- 通常是512字节的数据,但也可以选择
- 操作系统将自己的数据结构记录在磁盘上
- 将磁盘划分为几组cylinders,每组cylinders视为一个逻辑磁盘
- 逻辑格式化Logical Formatting分区以在其上创建文件系统
- 一些FS预留了备用扇区来处理坏块
- FS可以进一步将块分组到集群中以提高性能
- 磁盘I/O以块方式完成blocks
- 文件I/O以集群方式完成cluster
- 如果分区包含操作系统镜像,则初始化引导扇区
- 根分区包含操作系统,其他分区可以存放其他操作系统、其他文件、系统或为原始分区
- 在引导时安装Mounted
- 其他分区可以自动或手动挂载
- 对于想要进行自己的块管理的应用程序,可以访问原始磁盘,避免操作系统(例如数据库)
- 引导块初始化系统
- 存储在引导分区引导块中的引导加载程序
- 处理坏块的方法,如扇区保留
Swap Space Management
- 当DRAM容量不足以容纳所有进程时,用于将整个进程(交换)或页面(分页)从DRAM移动到辅助存储
- 操作系统提供交换空间管理
- 二级存储比DRAM慢,因此优化性能很重要
- 可能的多个交换空间-减少任何给定设备上的I/O负载
- 最好有专门的设备
- 可以在单独的分区中,也可以在文件系统中的一个文件中(为了方便添加)
- Linux系统上交换的数据结构:
- 0表示未使用
- 3表示映射到3个proc
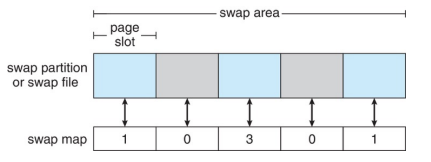
Lecture 14
RAID
- 磁盘不可靠,速度慢,但是便宜
- 我们用冗余增强其可靠性、增加速度
- Redundant Array of Independent Disks (RAID)
IO
OverView
IO设备的特点
- IO设备多样
- 每一个IO设备的差别很大
- 我们怎么管IO?
操作系统怎么访问IO
- Polling:轮询
- Interrupt
IO Hardwaare
- CPU有IO的指令
- 设备有IO设备的寄存器
- 和CPU交互:通过IO指令、将设备的寄存器映射到内存地址空间、读写内存地址就是读写设备寄存器。
Polling
对于每一个IO操作:
- busy-waiting如果设备是busy的
- busy时不能接受command
- 发一个command给device controller,通过command register
- 主动问设备,设备忙,OS做busy waiting
- 设备慢了的话,busy waiting的时间长
Interrupt
- 发一个command给device,然后去做别的事情
- device结束了会interrupt
- os调用interrupt handler
- 要进行context switch
- 因此一个设备很快的话,就用polling,避免context switch
- 有一个Interrput table
中断也用于异常
- 访问违规protection错误
- 内存访问错误
- 软件中断
CPU affinity
DMA
DMA直接在I/O设备和内存之间传输数据
- 操作系统只需要发出命令,数据传输绕过CPU
- 没有编程的I/O(一次一个字节),数据以大块传输
- 它需要在设备或系统中使用DMA控制器
设备的数据不经过CPU直接进入memory
Application IO Interface
I/O系统调用将设备行为封装在泛型类中
- 在Linux中,设备可以作为文件访问
- 使用ioctl的低级访问
Characteristics of IO Device
- 每个设备的差异性大,很不同
- 一读就是一个Block,或者一个字符流
- read&write、write only、read only
- synchronous or asynchronous
Lecture 15
Linux IO
Everything is a file,所有东西都是文件
- device下也有文件:/dev/ptmx,device有一个自己的文件,操作device,就对文件进行读写以操作
- 如何把device link到fops:cdev_init中cdev指向了ptmx_fops
- ptmx_fops.unlock_ioctl = tty_ioctl
- file_operations:都是函数,对文件的操作
- unlock_ioctl
File System Interface
Mass Storage
现在我们有了mass storage和IO,如何使用他们?
操作系统管理硬件,抽象成了文件系统:
- 文件会消耗disk上track/sector等资源
- 对于用户process而言,file是一个连续的block的bytes
- 文件系统有保护系统
文件的分类:
- 用存储的数据来分类numeric、character(text)、binary
- program
- proc file system:使用文件系统接口来检索系统信息,只有内存的buffer,没有disk上的映射。也称为in memory file system。
File Attributes
- Name、Identifier、Type、Location、Size、Protection、Time/date/user identification
File Operations
- Create:找到一个空间,申请一块entry在directory中
- Open:所有的操作要先打开,将文件的源信息load到内存里
- Read/Write:需要有一个pointer指向现在要操作的地方
- seek:挪动pointer
- close:释放掉fd
- delete:删掉一些文件
- truncate:清空文件,但是保存attributes
- copy:create、read、write
Open Files
需要一些数据来管理文件的打开
- Openfile table:追踪打开的文件
- File pointer:指向上一次操作的地方
- File-open count:全局的,允许从打开的文件表中删除数据时,最后进程关闭它
Lock:
- shared lock:多个read可以share
- Exclusive lock:有写的不可以share,使用exclusive
Lock Mechanisms:
- Mandatory强制锁:根据持有的锁和请求的锁拒绝访问
- Advisory咨询锁:进程可以发现锁的状态并决定要做什么
文件的类型
如何判断文件的类型?使用后缀?
使用Magic Number
- executable(exe,com,bin,none)
- object(obj,o)
文件的结构
一个文件可以有不同的结构,由操作系统或程序决定
- no structure:一串字节或单词的流
- 简单的记录结构
- 记录行,固定长度或可变长度,例如数据库
- 复杂的结构例
- 如:word文档,可重定位的程序文件通常用户程序负责识别文件结构
Access Method
- 访问文件有顺序访问、直接访问
- Sequential access:只能从头开始一个一个访问
- Direct access:支持直接访问文件中指定的位置
- 使用index实现Direct access
Directory Structure
一个disk文成不同的partition,一个partition 有一个文件系统。
- 有meta数据,存储文件系统的数据
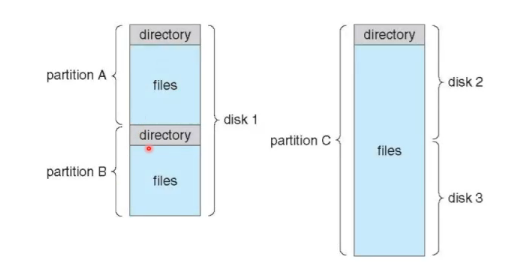
- Directory是包含所有文件信息的节点的集合
- 可以理解为,这个node里面存的是文件的metadata而不是直接的数据
- 目录就是一个nodes的集合
Directory Organization
- 组织目录以实现
- 效率:快速定位文件
- 命名:组织目录结构方便用户
- 两个用户对不同的文件可以有相同的名称,同一个文件可以有几个不同的名称
- 单级目录:
- 一个目录给所有用户用
- 命名问题和分组问题
- 两个用户希望拥有相同的文件名
- 一个目录给所有用户用
- 二级目录:
- 先有用户的目录,就是说用户每一个人都有自己的一个目录
- 然后再用户目录下保存用户的文件
- 共享?使用一个Dummy目录,所有用户都可以用
- Tree Based:
- 由Path演化而来
- 树形结构
- 可以使用绝对路径名或相对路径名访问文件
- 创建文件:touch
- 删除文件:rm
- 创建子目录:mkdir
- 删除目录:rm -rf 递归删除
Acyclic-Graph Directories
无环图:允许链接到目录条目/文件进行别名(不再是树)
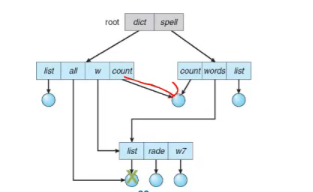
如果一个被连接的文件被删除,会有bug发生。
backpointer:有回指的指针,当有link指向它就不会被删除。
Genral Graph Directories
不要求无环,可以随意指。
允许循环,但使用垃圾收集回收磁盘空间
每次添加新链路时,使用循环检测算法
File System Mounting
- 文件系统必须先挂载Mount后才能被访问
- 挂载将文件系统file ops链接到系统,通常形成一个单一的名称空间
- 要挂载的文件系统的位置称为挂载点
- 挂载的文件系统使挂载点上的旧目录不可见,就是进行了一个替换,将旧目录替换成新挂载的目录
File Sharing
- 在多用户系统上共享文件是可取的
- Network也可以进行共享,如FTP
- Client-Server model:一个server发送信息,多个user从上面下载
Protection
- 要控制文件的访问的权限:能做哪些事?谁能做?
- Linux中使用了ACL:Access Control List
- 优点:细粒度控制
- 缺点:如何构建list,list存在哪里?
Lecture 16
File-system structure
- 文件是一种逻辑存储单元,用于收集相关信息。
- 有许多文件系统:操作系统可能同时支持几种
- 文件系统位于二级存储(磁盘disk)上
- 提供读和写的接口
- 文件系统通常被实现并组织成层
Layered File System
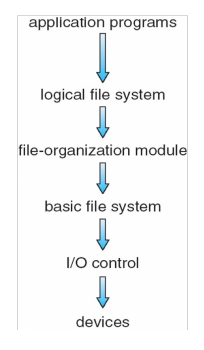
- Logical file system
- 保留文件系统所需的所有元数据
- 它存储目录结构
- 它存储一个存储文件描述的数据结构(文件控制块- FCB)
- 以上输入:打开/读/写filepath
- 输出如下:读/写逻辑块
- file-organization module
- 了解逻辑文件块(从0到N)和相应的物理文件块,它执行转换
- 它还管理空闲空间
- 以上输入:读取逻辑块3,写逻辑块17
- 输出如下:读取物理块43,写物理块421
- basic file system
- Linux中的“块I/O子系统”
- 分配/维护包含文件系统、目录和数据块的各种缓冲区
- 这些缓冲区是缓存,用于提高性能
- 以上输入:读取物理块#43写入物理块#421
- 输出如下:读取物理块#43写入物理块#421
- IO control
- 设备驱动程序和中断处理程序
- 以上输入:读取物理块#43写入物理块#124
- 输出如下:写入设备控制器的内存以执行磁盘读,写对相关中断做出反应
File system Data structure
- 文件系统由数据结构组成
- On-disk
- 一个可选择的boot control block
- 存储操作系统中的卷的第一个块
- UFS中的boot block,在NTFS中存储分区引导扇区
- 一个volume control block
- 包含volume中的块数、块大小、free-block计数、freeblock指针、free-FCB计数、fcb指针等信息
- UFS中的super block,NTFS中的master文件表
- 一个Directory
- 与ID关联的文件名,FCB指针
- per-file File Control Block (FCB)
- 在NTFS中,FCB是关系数据库中的一行
- 一个可选择的boot control block
- In-memory
- 一个挂载表,每个挂载卷有一个条目
- 用于快速路径转换的目录缓存(性能)directory cache
- 一个全局的打开文件表global open-file table
- 一个per-process open-file table
- 不同的缓冲区保存“正在传输”的磁盘块(性能)
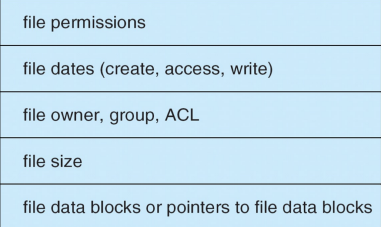
Typical File Control Block
文件的操作
Creation()
- 分配一个新的FCB,一个新的File control block
- 更新相应的目录,将file的指针等放入
open()
- 将FCB进行Load到内存中
- 寻找System-Wide Open-File Table看看这个文件是否在use了
- 如果打开过,创建一个Per-Process Open-File Table entry,指向存在的System-Wide Open-File Table就好
- 如果没找到,则找directory,将FCB从磁盘load到内存,放进Open-File Table
- 增加System-Wide Open-File Table中的open count
- returns a pointer to the appropriate entry in the Per-Process Open-File Table
- 所有后续操作都使用该指针执行
- process closes file -> Per-Process Open-File Table entry is removed; open count decremented
- all processes close file -> copy in-memory directory information to disk and System-Wide Open-File Table is removed from memory
Mounting File System
- 引导块——一系列连续的块,包含程序的内存映像,调用引导加载程序,定位并挂载根分区;分区包含内核;引导加载程序定位、加载并启动内核执行
Virtual File System
- Question:OS如何handle这么多类型的文件系统(EXT、FAT、NTFS...)?
- “All problems in computer science can be solved by another level of indirection,except for the problem of too many layers of indirection.”
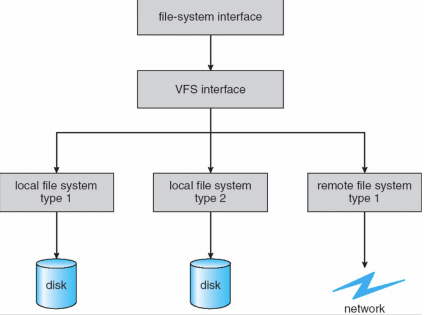
- 虚拟文件系统
- VFS提供了一种面向对象的实现文件系统的方法
- OS为FS定义了一个公共接口,所有的FS都实现了它们。
- 系统调用是基于这个公共接口实现的
- 它允许相同的系统调用API用于不同类型的FS
- VFS将FS泛型操作与实现细节分离
- 实现可以是许多FS类型之一,或网络文件系统
- OS可以将系统调用分派给适当的FS实现例程
- 我们调用时只用调用write、read等,底层会自动调用正确的文件系统的write、read函数
- Write syscall → vfs_write → indirect call → ext4_file_write_iter
- What’s the call path when writing a nfs file?
- Write syscall → vfs_write → indirect call → nfs_file_write_iter
- When is file-> f_op setted?
- f_op是指向不同文件系统的f_op的,这个f_op什么时候被set?
- 被open的时候,它知道它来自哪个文件系统了,它是in memory的data structure
Directory Implementation
- 目录是一种特殊的file
- 存储mapping,从file name 到inode
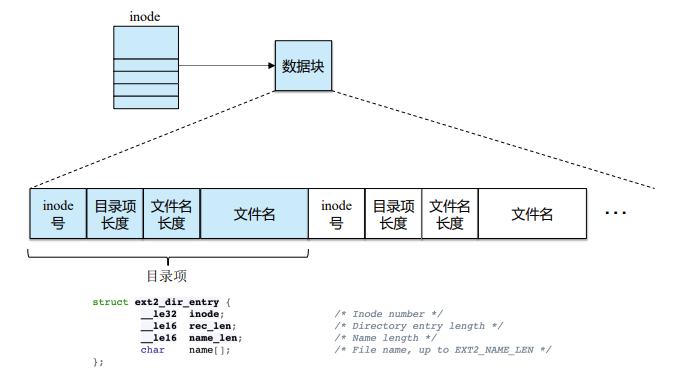
- Linear List
- 带有指向文件元数据指针的文件名的线性列表
- 需要一个一个对比,搜索时间长
- 编程简单,但搜索耗时(如线性搜索)
- B+树组织
- 按照字母表顺序
- 存hash table
- 具有哈希数据结构的线性列表
- 以减少搜索时间冲突是可能的:两个或多个文件名散列到同一位置
Disk Block Allocation
- 文件需要分配磁盘块来存储数据
- 不同的分配策略具有不同的复杂性和性能
- Contiguous Allocation
- 连续分配,每个文件都在一组连续的块中
- 好是因为顺序访问导致磁盘头很少移动,从而缩短了寻道时间
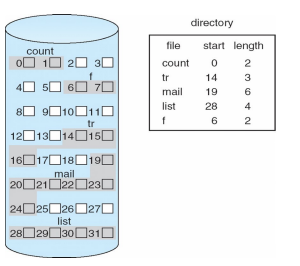
- directory包含了start和len
- 优点:
- 读一个block很快能读到,方便定位
- 缺点:类比连续的内存分配
- 找空闲空间困难
- external fragmentation
- 文件很难增长
- Linked Allocation
- 每一个block包含一个指向下一个block的指针
- 块可以分散在磁盘的任何地方(没有External Fragmentation,没有压缩)
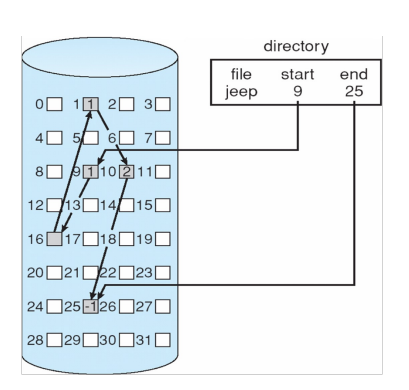
- 目录就只需要包含start和end的block
- 缺点
- 需要sequencial访问,比如要访问16,必须从9开始
- 容错率低,若16被损坏了,后面的都坏了
- FAT32使用的是Linked的,支持文件大小最大为4G
- 为什么是4GB?
- Indexed Allocation
- 索引分配,每个文件都有自己的指向其数据块的指针索引块
- 需要分配一个index block,对于小文件比较浪费
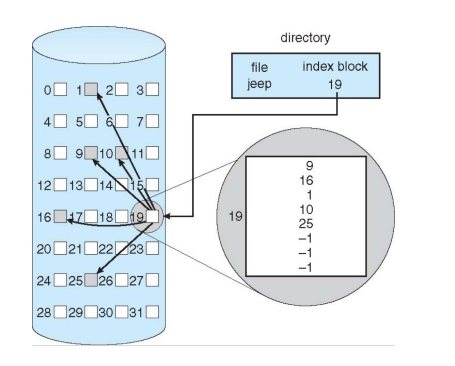
- 缺点:
- 浪费
- 改进:
- index大小可变
- index block可以指向index block
- linked index block
inode
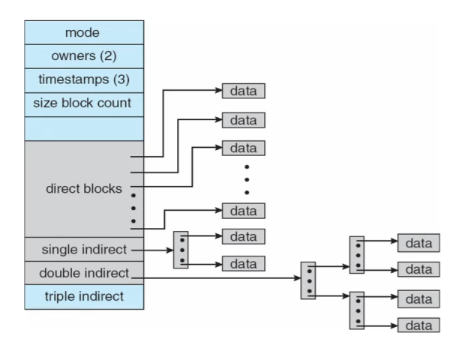
- 有15个data block的指针:
- 12个直接指向data block的指针
- 3个间接指针:single、double、triple
- 假如我们有一个block为512bytes,一个pointer为4bytes,那么文件最大有多大?
- \(Max Size = 12*512+1*(512/4)*512+1*(512/4)^2*512+1*(512/4)^3*512\ bytes\)
- 约等于1G
- 若block size为4KB?
- \(Max Size= 12*4K+(4K/4)*4K+(4K/4)^2*4K+(4K/4)^3*4K\ bytes\)
- 约等于4TB
- 前6KB可以直接找到block,越访问后面越慢!
1 | Linux的Ext文件系统是如何与磁盘内存产生对应的呢?我们知道,在使用磁盘内存之前,需要为磁盘分区,然后为所分区域格式化出一个统一的文件系统(也有例外,如LVM与磁盘阵列技术)。那么,在这样一个统一的文件系统中,根据数据的不同,就可以将内存分为以下3种类型: |
Free Space Management
Bit Map
使用比特来标记block是否被使用
- 一个block对应一个bit
- bit[i]=1,free
- bit[i]=0,occupied
- 例子:
- block size = 4 KB = 2^12 bytes
- disk size = 1TB = 2^40 bytes
- block number = 2^28
- 也就是说我们需要这么多个bits来表示,折合成Byte有32MB!
- 太浪费了
- 我们可以把多个block看成一个cluster,一个cluster用一个bit表示
Linked Free Space
将没有用的block进行link起来,不会浪费内存
缺点在于,我们IO操作很多!不能容易拿到连续空间。
- Grouping分组
- n个一组,在第一个空闲块中存储n-1个空闲块的地址,加上一个指针到下一个索引块
- 分配多个空闲块不需要遍历列表
- Counting
- 集群的链接(起始块+连续块数量)
- 经常连续地使用和释放空间
- 在链接节点中,保留第一个空闲块的地址和后面空闲块的编号
File System Performance
- 把metadata和data放得近一些
- 使用cache
- 用asynchronous writes,写cached/buffered
- read-ahead/free-behind:多读一些放进buffer
- 读通常比写慢,读涉及disk,写的时候已经在buffer里面了
Page Cache
- 缓存的是文件,所有的文件都在page cache中有一份,读写都在page cache中
- 多级的cache:以文件为力度存、以block为力度存IO block buffer,通常会有double cache,同一个被cache了两次,又浪费
Recovery
- 文件系统需要可以recover
- backup,使用冗余
- log-structured File System
Log-Structured File System
- LSFS,基于日志的文件系统
- 更新的元数据按顺序写入循环日志
- 比如我们现在写这个文件,日志中添加写操作,并没有直接写。
- 同时,我们有线程,会把log entry进行慢慢执行,这时才会真正写。
- 当system crash了,我们只需要根据log进行恢复即可
Lecture 17
File System in Practice
- File
- 字节的线性数组,每个字节都可以读/写
- 有一个低级的名称(用户不知道)- inode号
- 通常操作系统不知道文件的确切类型
- 目录
- 有一个低级名称
- 它的内容非常具体:包含用户可读的ame到低级名称的列表。Like ("foo", inode number 10)
- 每个条目都指向文件或其他目录
File
- External Name:人读的名字
- Internal Name:Low-Level Names即inode number
- 相当于序列号,存着一些pointer,之前提到的
Directory
- 从External外部名称转换为Internal内部名称
- inode到external name的映射
操作
Create file
int fd = open("foo",O_CREAT|O_WRONLY|O_TRUNC)一般不返回inode,返回给user也不理解,fd是什么?
一个file descriptior,类似一个文件编号一个句柄。文件在file desciptor table中的index
Write and fsync
- 写到buffer中,buffer每隔一段时间会同步一下
- 或者用fsync强制同步写磁盘
获得inode信息
stat foo即可获得文件信息
Remove file
Hard link vs Soft link
- Hard link
- 硬链接是与文件相关联的目录条目,是一个目录项,指向一个文件
- 目录中的文件名“.”是到该目录本身的硬链接
- 文件名“..”是到父目录的硬链接
- hard link没有inode
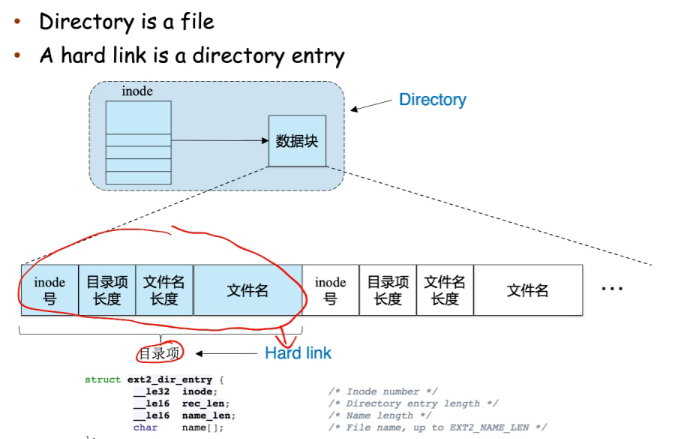
- 一个hard link是一个目录中的目录项,目录有inode,目录项没有inode
- Soft link
- Symbolic链接是包含路径名的文件另一个文件,是一个文件
- 有自己的数据块,数据块存的内容是path to target file
- 有inode
- 轻量级的是hard link,不涉及inode分配
FS
- VFS:inode
- In-memory data structure:ext2_inode_info
- On-disk data structure:ext2_inode
【Example】
假设我们有64个block,每一个block为4KB,我们有256KB的disk
我们会有56个存data,8个存metadata(其中5个存inode,假设一个block有16个inodes,那么我们有80个inode),还有三个block,两个给bit map,一个是bitmap给free inode的,一个是给free data region的,剩下一个给文件系统的superblock。
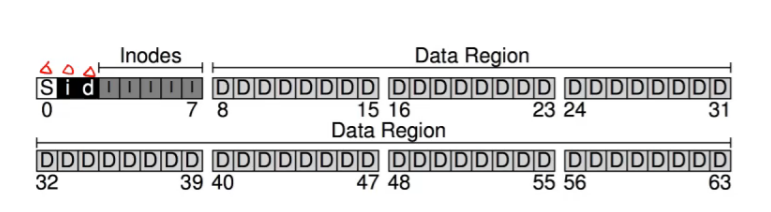
inode address calculation
假设我们的inode是256bytes,4KB的block有16个inode,那么5个block就有80个inode,那就可以有80个files(directories)。
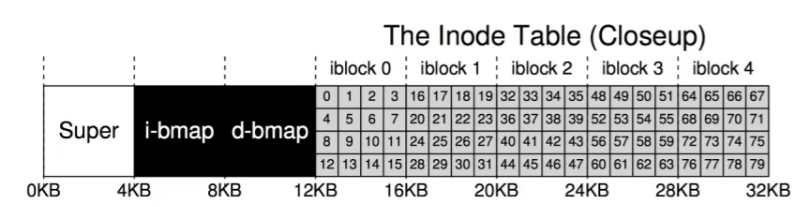
每个inode有number,叫做inumber
想要读inumber = 32的inode
- \(4K+4K+4K+32*256bytes=20K(bytes)\)
inode里面就有data pointer了,就可以访问data了!
Directory的组织
假设我们的dir有三个文件foo,bar,foobar
- inode number,name
- strlen:名字的长度
- reclen:名称的长度加上剩余的空格
- 用于重复使用入口的目的
分析
- 读 /foo/bar
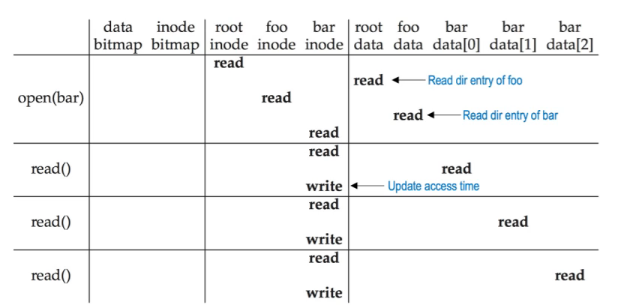
- 读root inode的data里面有目录项即foo的inode
- 读foo的data找到里面的目录项,拿到bar的inode
- 把bar的inode拿出来
- 写 /foo/bar
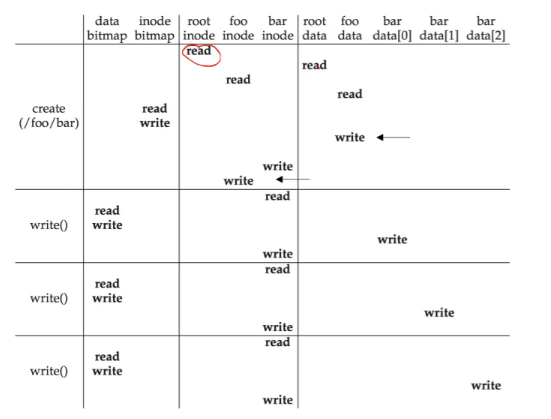
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !