1. Entity Sets
1.1 Entity Sets实体集的定义
- 世界能被模型化为:许多实体Entities和实体间的联系Relationships
- 实体是存在可分别的对象,可抽象可具体
- 实体具有属性Attributes
- 实体集Entity set是一系列相同类型的实体,有着共同的属性
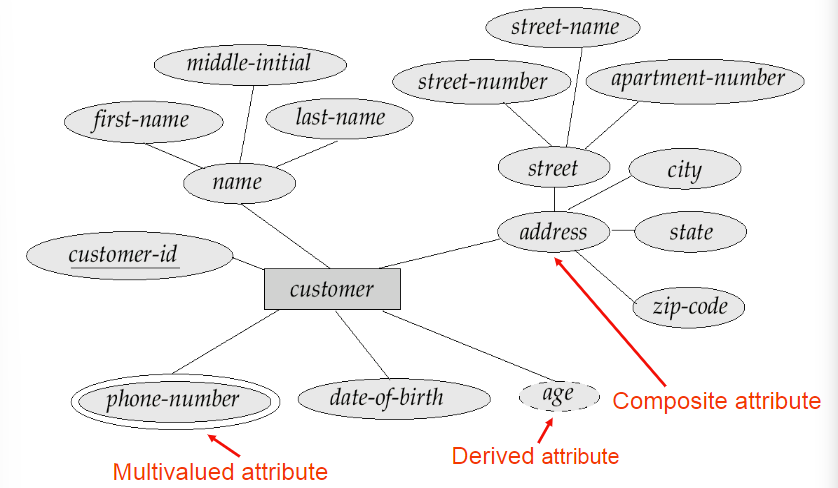
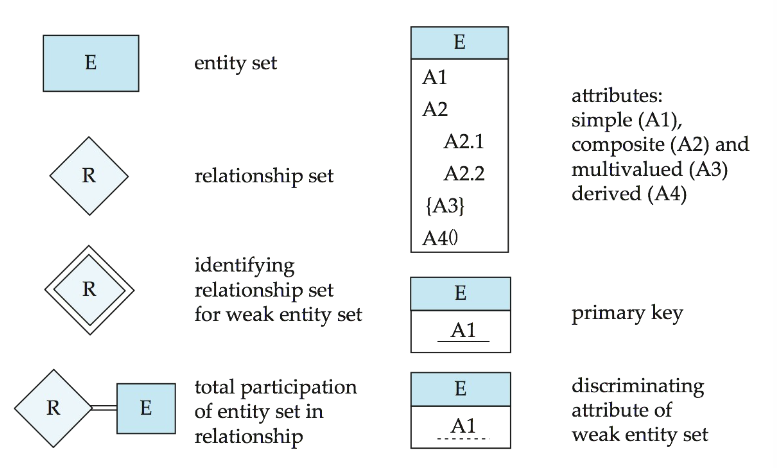
1.2 Attributes属性
- 一个实体有一系列的属性
- 域Domain(Value set)是属性的取值集合
- 属性的种类:
- 简单属性:sex
- 复合属性:name(由first name和last name组成)
- 单值属性:birthday
- 多值属性:phone(可能有多个电话)
- 派生属性Derived attributes:能从其他属性中计算出来,如age可以从birthday中计算,有基属性或者储存属性
2. Relationship Sets
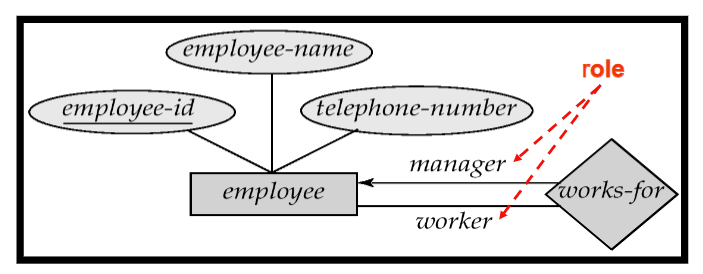
一个关系可以是多个不同类实体之间的关系,也可以是自关系
1
2
3
4borrower(Jones,L-17)
relationship(customer-entity,loan-entity)
manager(001,002)
relationship(workerid,workerid)联系集是多个同类联系的集合
对于许许多多的特定的两个实体组有关系R1、R2、R3…这些关系有相同的类型,那么R就是关系集
2.1 关系的表示
2.1.1 集合的表示
${ (e_1,e_2,…,e_n)|e_i∈E_i,i=1,…,n}$
这里,$(e_1,e_2,…,e_n)$是一个关系,$E_i$是实体集
2.1.2 table中的表示
对于二元关系一般用两个实体集的主码来表示,当然可以添加一些其他的属性,这是关系的属性
Example
Student的主码为Sid
Course的主码为Cid
那么参与课程的学生的期末成绩
$Marks(Sid,Cid,grade)$
2.2 Degree关系集的度
定义: 引用的实体集的个数(如二元集度数为2)
关系集可能不止两个实体集,但是比较稀少,并且多元关系可以转化为多个二元关系
2.3 Mapping Cardinalities映射基数
定义: 在一个联系集中,一个实体可以与另一类实体相联系的实体数目,数目指的是最多一个还是可以多个
种类:
1-1 , 1-n , n-1 , n-m
3. Keys
3.1 实体集的keys
- super key: 能够唯一决定实体的单个或者多个属性
- candidate key: 候选码是最小的super key
- 可能存在很多的候选码,我们在选择主码的时候要谨慎(
3.2 关系集的keys
- 参与关系集的各实体集的主码的组合构成一个关系集的超码
- 作为主码的属性不可为空
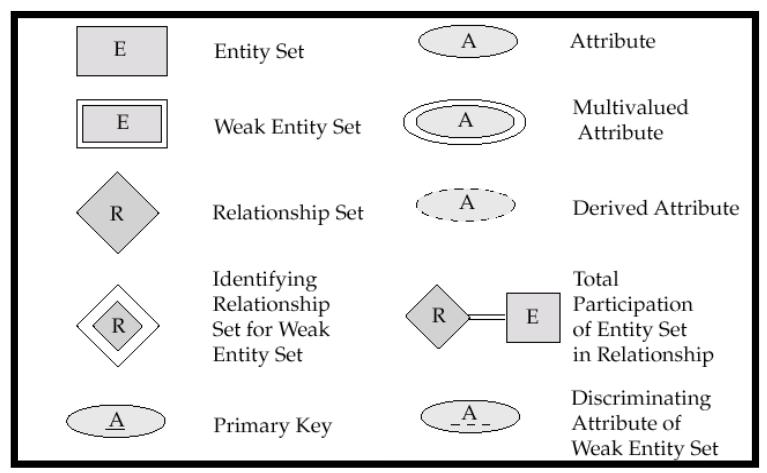
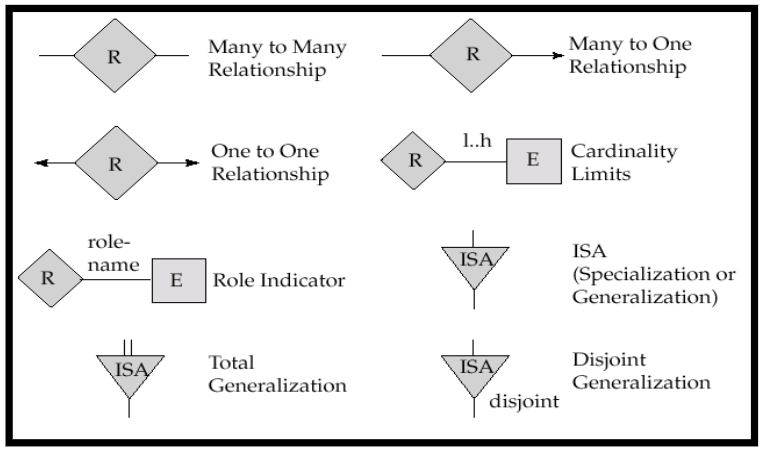
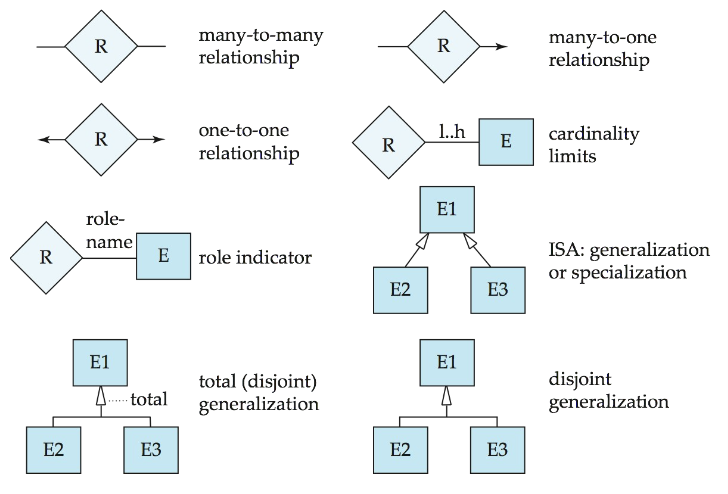
4. E-R Diagrams
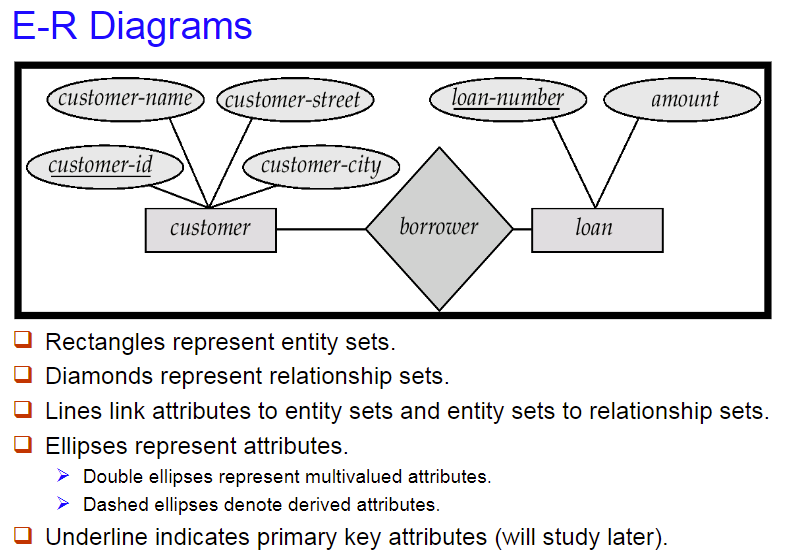
4.2 不同类型的属性表达
 >
>
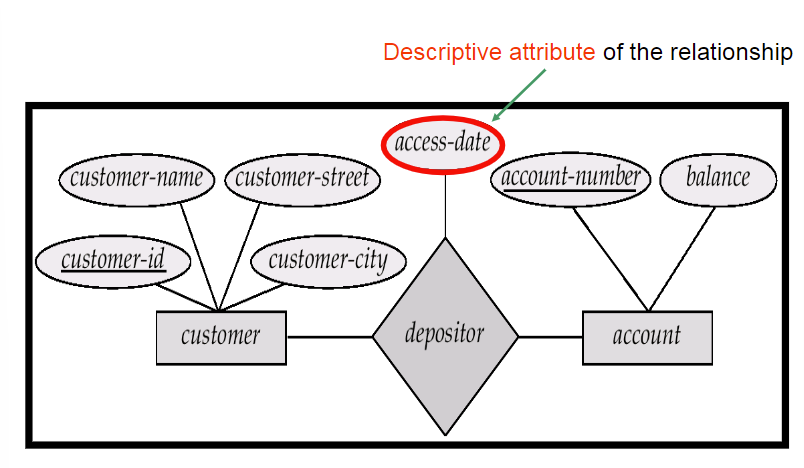
4.3 关系集的属性的表达
4.4 自关系和Role的表达
4.5 映射基数的表达
箭头(→)指的是one
直接的线(—)指的是many
从而在二元关系上表达映射基数种类
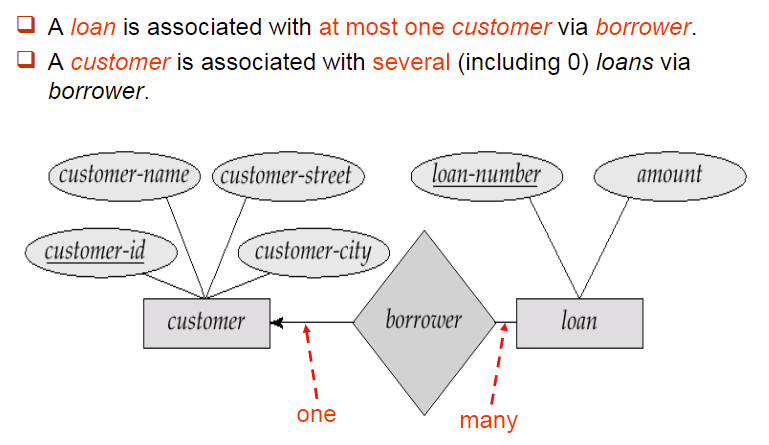
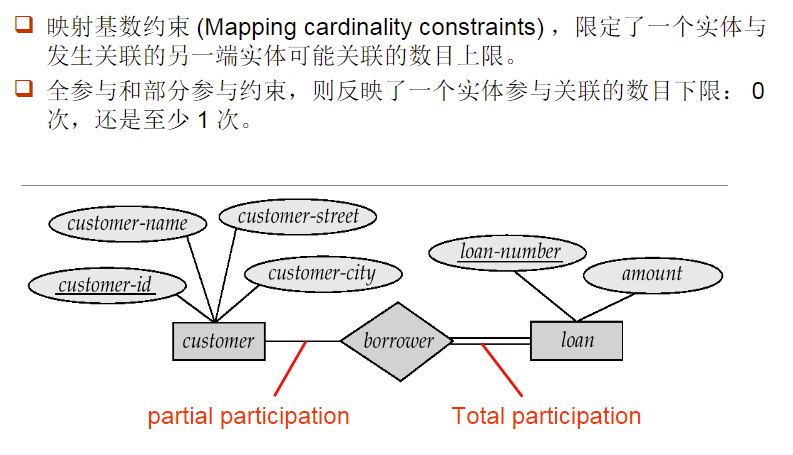
4.6 全参与与部分参与
- Total Participation: 实体集中所有的实体都参与了这个关系
- 全参与我们使用双横线表示
- Partial Participation: 实体集中部分的实体参与了这个关系
- 部分参与直接用直线
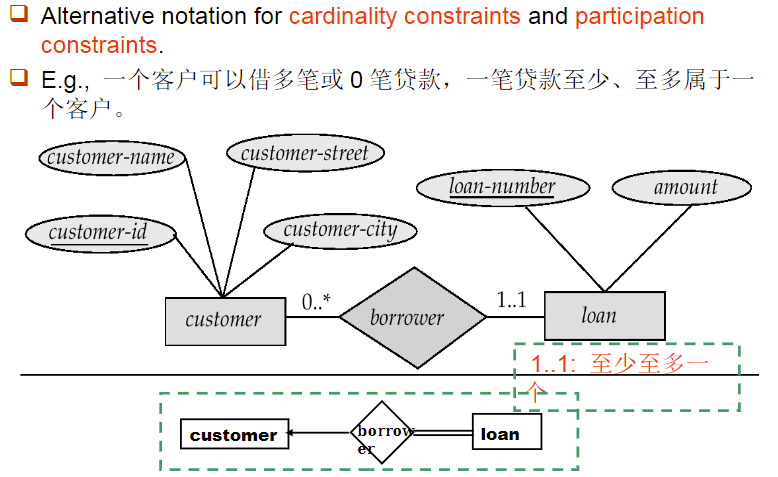
4.7 关系约束的替代信号
如果不想用复杂的箭头和双横线,可以在实体集和关系集之间的横线上可以使用$x..y$的信号,表示最少x个,最多y个参与关系
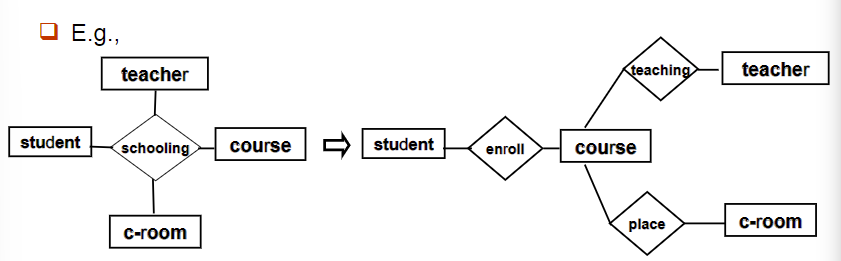
4.8 多元关系
多元关系可以转化为多个二元关系
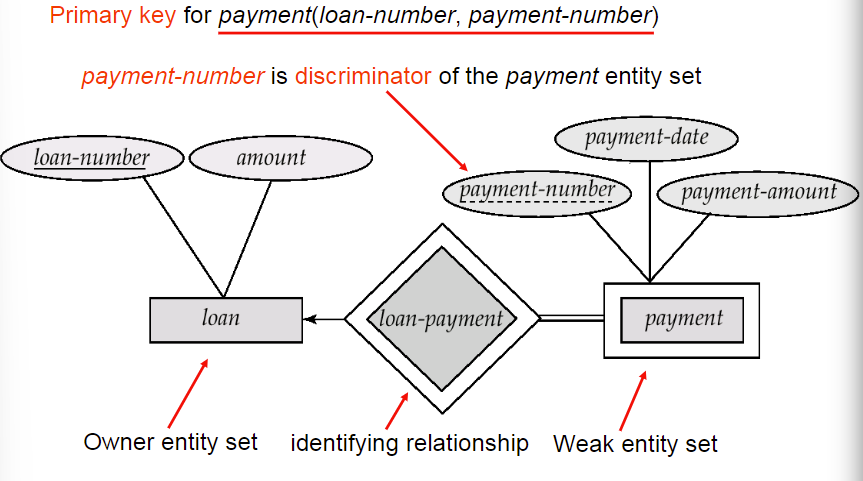
5. Weak Entity Sets
- 定义: 一个实体集没有主码即为弱实体集,使用双框矩形表示
- 弱实体集单独存在不具有实际意义,它必须依赖于一个确定的实体集,要与一个确定实体集建立关系,这里的关系我们使用双框菱形
- discriminator鉴别符是在弱实体内部鉴别使用的,使用虚线下划线表示
- 弱实体的主码是由强实体集的主码+弱实体的鉴别符组成的
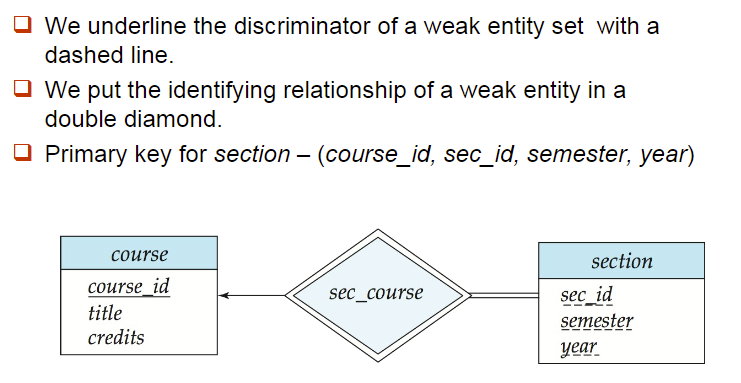
- 注意:强实体集的主键没有显式地与弱实体集存储在一起,因为它在标识关系中是隐式的。如果显式地存储了course_id,则可以将section作为一个强实体,但是section和course之间的关系将被一个由course和section共同的属性course id定义的隐式关系复制
6. Extended E-R Features
6.1 Specialization(特殊化、具体化)
- 一种top-down的设计过程
- 设计的实体集可以从上层的实体集继承派生而来
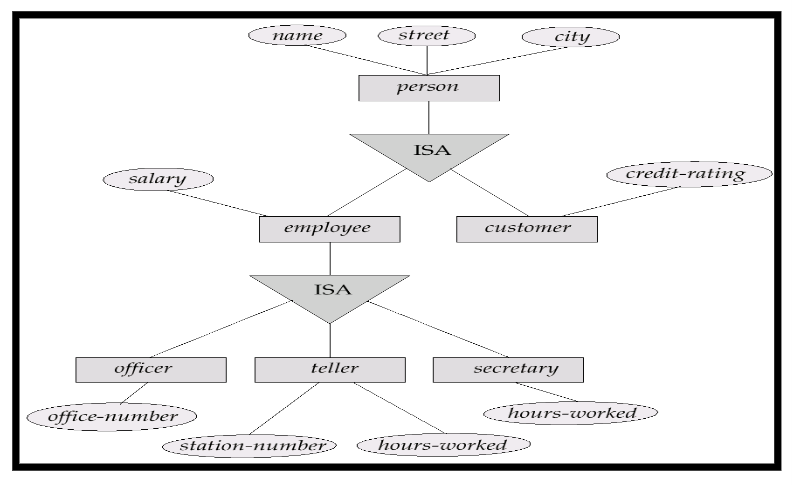
6.2 Generalization(泛化、普遍化)
- 一种bottom-up的设计过程
- 把下层具有相同属性的实体集生成新的父类
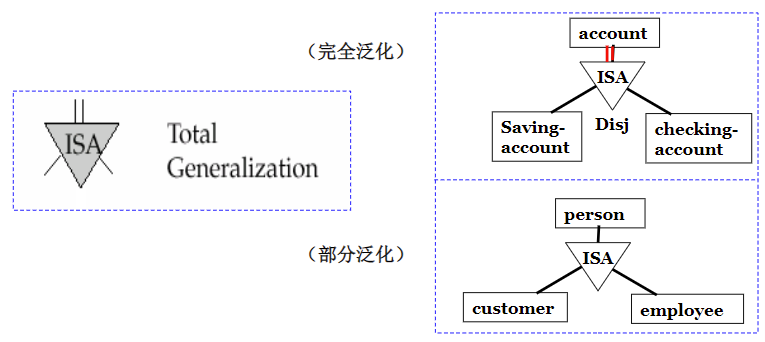
6.3 Specialization和Generalization的设计方式
用**倒三角(加上ISA)**表示继承,子类可以在父类的基础上额外增加属性
在倒三角下方加上Disj表示不相交,即一个父类如果成为了子类要么是子类A要么是子类B,不可能同时为A和B
倒三角上方使用双线表示父类全参与,所有的父类都要成为子类
6.4 Aggregation聚合
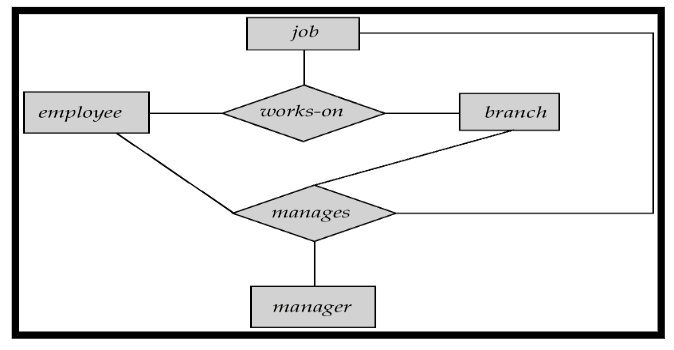
在这个ER图中,manager管理着works-on的所有实体集,我们可以把上方的所有集合看成一个复合实体集,更加方便地表示,即为聚合
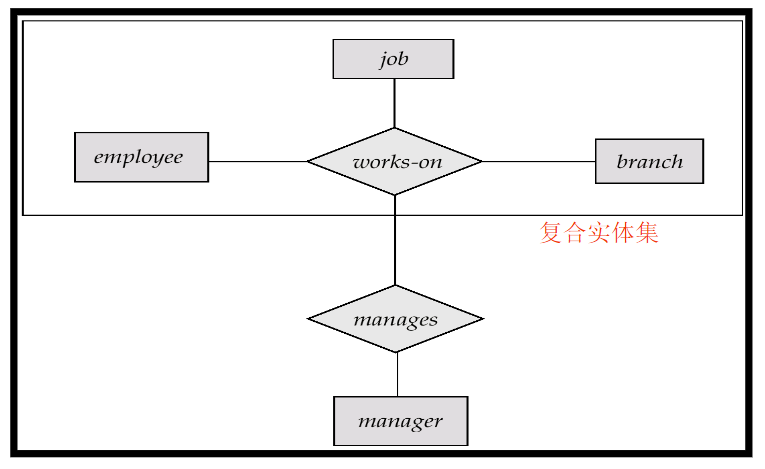
6.5 ER图的整理
7. Design of an E-R Database Schema
设计Database的步骤:
- 需求分析
- 概念模型设计(ER图)
- 逻辑模型设计(关系模式表结构)
- 物理模型设计(储存模式)
要考虑的事情:
- 用属性attribute还是实体集entity set表示一个对象?如多值属性怎么表示?
- 将其当作entity set还是relationship set?relationship set是两个entity set之间动作的表示
- 将其当作attribute of an entity还是relationship? 不要在一个实体集中添加太多的无关属性,可以用新的实体集加关系来表示,减少冗余
- 用n元关系还是一些二元关系?
- 用强实体还是弱实体?
- 是否需要用继承、派生、泛化?有助于模块化
- 是否需要聚合?
8. Reduction of an E-R Schema to Tables
- 一个数据库可以从ER图中获得一系列的table
- 每一个实体集和关系集都有表对应
8.1 表示方法
强实体集: 变成有相同属性的表
复合属性: 拆开成为单个有原子性的属性
多值属性: 将多值属性拆成表,如
1
2
3
4employee(emp-id,ename,sex,age,dep-names)
employee(emp-id,ename,sex,age)
employee-dept(emp-id,dept-name)弱实体集: 加入关联强实体的主码,成为表
关系: 关系的实体集的主码,(成为表的外码)和关系自带的属性写成一个表
8.2 表的冗余的处理
在一对多的关系中,可以将联系表合并如多端的实体中
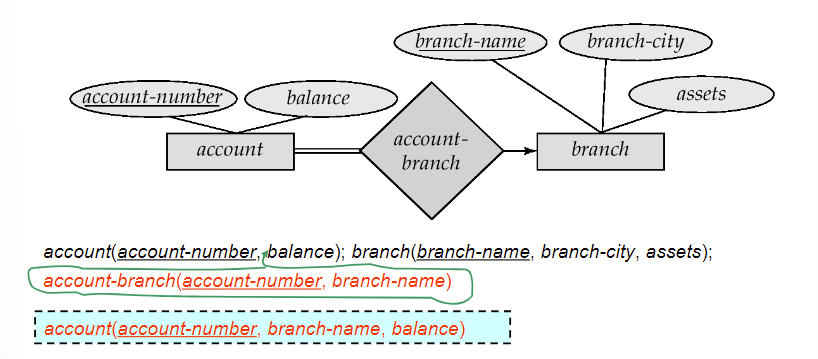
一对多的合并,有些部分参与的实体集合的关系并为table要合并到many的一端,并且要设置为可以为NULL Values
一对一的关系集可以任选一边作为”many”

在强弱实体集的关系中,这个关系identifying relationship其实是多余的,因为弱实体的表已经包含了强实体的主码
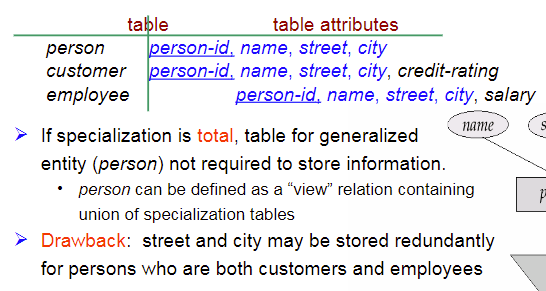
8.3 Specialization的表示
建立父表,在子表中包括父表的主码

建立父表
9: Relational Database Design
1. First Normal Form
第一范式: Domain is atomic: 域是原子的,不可再分
有非原子的域要拆分为有原子性的如:
- Composite attributes — set of names
- Multi-value attribute — a person’s phones
- Complex data type— object-oriented
2. Pitfalls in Relational Database Design
2.1 错误的设计
错误的设计导致的问题:
- 内存冗余
- 删除、插入、更新操作出错
一个常见的错误设计:把无用的属性加入实体集中,导致实体集冗长,应该要采用top-down或者button-up的设计方式,因此我们需要分解!
2.2 分解
分解是把一个冗长的关系、实体分解为小的关系、实体。
如把原始的模式R分解为($R_1,R_2$),那么R的所有属性要出现在$R_1∪R_2$中,且分解要保证是无损分解,即
$r=\prod_{R_1}(r)\Join \prod_{R_2}(r)$
Example:

3. Functional Dependencies
函数依赖性定义:若$t_1[\alpha]=t_2[\alpha]$则一定有$t_1[\beta]=t_2[\beta]$
那么我们称β依赖于α,α决定β,即α的值唯一确定时,β的值也唯一确定
记作α→β
3.1 函数依赖性和key的关系
- 函数依赖性是key的一种泛化
- K是superkey,等价于K→R
- K是candidate key,等价于K→R且不存在α是K的真子集,且α→R
- 我们可以写出函数依赖集从而找出最小的闭包从而确定key
函数依赖集:F={a→b,c→d,a→e,…}
- Example:

3.2 函数依赖性的应用
Example:
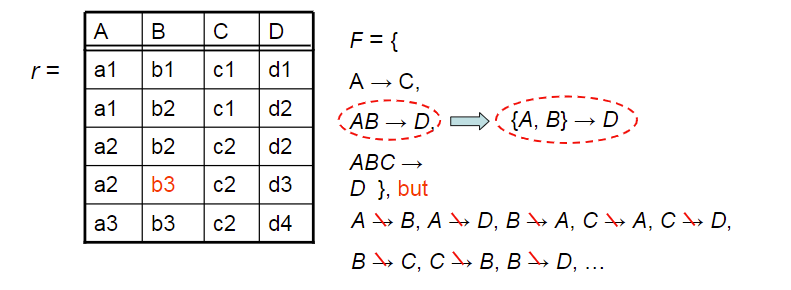
我们容易判断一个r是否满足给定的F,但是不易判断F在R是是否成立,我们使用函数依赖集来判断
3.2.1 平凡和非平凡的依赖性的定义
平凡的(trivial):α→β,if β$\subseteq$α
非平凡的(Non-trivial):α→×β,if β$\subseteq $α
我们一般关注非平凡的函数依赖,平凡的函数依赖一般来说比较弱
1 | (customer-name,loan-number)→customer-name |
3.2.2 函数依赖性的闭包
定义:给定一组函数依赖性F,还有一些其他的函数依赖性在逻辑上由F隐含,所有的函数依赖性合起来就是函数依赖集F的闭包记作$F^+$。
Example:
$F={A→B,B→C}$
$F^+={A→B,B→C,A→C,A→A,AB→B,AC→C…}$
3.2.3 如何找闭包?
使用Armstrong’s Axioms:
- 自反律:若$\beta\subseteq \alpha$则$\alpha→\beta$
- 增补律:若$\alpha→\beta$则$\gamma\alpha→\gamma\beta$(且$\gamma\alpha→\beta$)
- 传递率:若$\alpha→\beta且\beta→\gamma$则$\alpha→\gamma$
- $合并律^$:*若$\alpha→\beta且\alpha→\gamma$则$\alpha→\beta\gamma$
- 分解律$^$:*若$\alpha→\beta\gamma$则若$\alpha→\beta且\alpha→\gamma$
- 伪传递律$^$:*若$\alpha→\beta且\gamma\beta→\delta$则$\alpha\gamma→\delta$
使用定律可以从已有的依赖中求出其他依赖关系
3.2.4 如何判断a是不是一个superkey?
使用属性闭包!
Method 1:找到闭包依赖函数集$F^+$,若a→$\beta_i$对所有的$\beta_i$属于$F^+$成立则a是一个superkey
Method 2:找a的闭包$a^+$
a的闭包:
F下所有被a直接或者间接决定的的属性的集合为a的闭包记作$a^+$
如果$a^+$决定了R,即a→R is in $F^+$,则a是superkey
3.2.5 画图找闭包的方法
决定和依赖关系使用箭头表示,如图
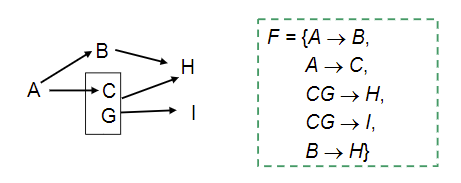
则,没有箭头指向的一定是候选码(AG)再验证AG的闭包是否为全集即可
3.3 属性闭包的总结
测试superkey
检查$R\subseteq \alpha^+$
测试函数依赖性
检测α→β是否成立只需测试$\beta\subseteq \alpha^+$
计算F的闭包
每一个$\gamma \in R$,我们可以找到闭包$\gamma^+$,这个闭包是属于$F^+$的
3.4 Canonical Cover正则覆盖
我们要简化依赖函数集合F,使得F不仅和$F^+$等价而且要规模最小
我们把这个正则覆盖记作$F_c$,它是一个最小的FDs(Functional Dependency),等价于F
特点:
- 没有冗余的FDs
- FDs中没有冗余的部分,即FDs中不要有无用的属性如A→BC,B→C,直接写A→B,B→C即可
- 每一个左边的值是唯一的unique
如何获得$F_c$:
- 合并率,将左侧相同的依赖函数合并为一个,如${A→B,A→E,…}$合并为${A→BE,…}$
- 在合并完的函数依赖集中寻找一个无关属性,删除它
何为无关属性及其判断:
右侧判断
如F={A→BC,B→AC,C→AB}
关注B属性。它在依赖右侧。删除该属性,余下F’={A→C,B→AC,C→AB},计算左侧剩余属性集(A)的闭包$A^+$。因为A→C,C→AB,所以$A^+$中包含删去的属性B。故B是无关属性左侧判断
若要判断的属性位于依赖的左侧,例如{undefinedAB→C},则删除该属性,在原本的依赖集F中计算该依赖左部集合的闭包α+。若α+闭包中包含该依赖右侧所有的属性,则该属性则是无关属性,如函数依赖集F={Z→X,X→P,XY→WP,XYP→ZW}
关注到XYP中的P属性。它在左侧。删除它,求解左侧剩下属性集XY的闭包,求取域是原来的F{Z→X,X→P,XY→WP,XYP→ZW}。因为XY→WP,所以(XY)+ = XYWP;又因为XYP→ZW,所以(XY)+ = XYWPZ,包含依赖右侧ZW。故P是无关属性
4. Decomposition
4.1 分解的要点
- 分解要是无损分解
- 依赖保持
- 每一个子关系是good form(BCNF或者3NF)
4.1.1 无损分解的要点
- 分解后的两个子模式的共同属性必须是R1或者R2的码
- 一定是要码!!!
- 即${R_1∩R_2}→R_1orR_2$
4.1.2 依赖保持
R的依赖关系F,$R_1$的依赖关系有$F_1$,$R_2$的依赖关系是$F_2$,这里的F1和F2一定是在F的闭包$F^*$之中的,我们所说的依赖保持指的是
$(F_1∪F_2)^*=F^*$
多元的分解也是如此:
$R_i$的依赖$F_i\subseteq F$,
$(F_1∪F_2∪..F_n)^*=F^*$
5. Boyce-Codd Normal Form
BC范式定义:
- 每一个表中所有的函数依赖α→β,至少满足一条
- α→β是平凡的
- α是R的superkey
一个表中只剩下两个属性,那么一定满足BC范式
不满足BC范式的模式可以分解为BC范式的形式
- Example:

5.1 表的BCNF的验证
不能仅仅使用依赖函数F来验证!

例子中,码是(A,D),而A→B,B→C,AB均不是码,因此不满足BCNF,因此我们需要分解为BDNF。
$F^*={A→B,B→C,A→C}$
$R_1:F_1={A→B}$
$R_2:F_2=A→C$
这样子R2仍不是BCNF,因为A→C这个依赖关系被继承下来了
5.2 如何分解为BC范式
为什么不是BC范式:因为有A→B,而A不是key也不是B的子集
我们怎么做:通过分解让A成为key
- Example

首先看一下原来的表是不是BCNF:
候选码:{loan-number,customer-name}
注意到branch-name →{branch-city,assets}中branch-name不是key
$R_1=(branch-name,branch-city,assets)=(\alpha,\beta)$
$R_2=(branch-name,customer-name,loan-number,amount)=R-\beta$
但是此时的R2还不是BCNF,因为
loan-number→{amount,branch-name}中loan-number不是key
继续分解直到满足BCNF
5.2 为什么有时不用BCNF?
因为在保持依赖性和减少冗余之间有冲突
Example:丧失函数依赖性的例子

6. Third Normal Form
定义:对所有的依赖函数集闭包中的依赖关系α→β,至少满足
- α→β是平凡的
- α是key
- 对每一个属性A∈β-α,A是R的某个候选码的一部分(又称A为主属性)
6.1 如何构建第三范式
把正则覆盖$F_c$中的所有α→β分解为子模式$R_i=(\alpha,\beta)$
参见:https://blog.csdn.net/sumaliqinghua/article/details/86246762
7. Multivalued Dependencies
目前我们要求最高的范式是BC范式,但是有时BCNF并不是冗余最小的
有时表无法找到依赖关系,且key是全部的属性的组合,这么做仍然是满足BCNF的,但是仍有很多的冗余。

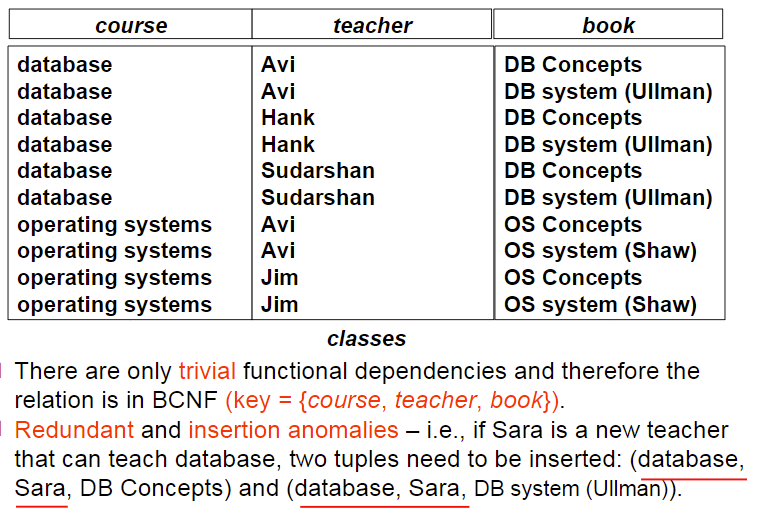
可以看到这张表是满足BCNF的,但是能明显看出有很多的冗余。这是因为之前所说的依赖关系是建立在一对一的基础上的,一对多没有定义一种依赖关系。
7.1 多值依赖关系MVDs
定义:存在$t_1[\alpha]=t_2[\alpha]$,则存在$t_2[\alpha]=t_4[\alpha]$,且
$t_3[\beta]=t_1[\beta]$
$t_4[\beta]=t_2[\beta]$
$t_3[R-\alpha-\beta]=t_2[R-\alpha-\beta]$
$t_4[R-\alpha-\beta]=t_1[R-\alpha-\beta]$
那么β多值依赖于α,α多值决定β,记作α→→β
- 如果α→β则α→→β

8. Fourth Normal Form
定义:对于多值依赖函数集合的闭包$D^+$中的所有α→→β,一定满足其一:
- α→→β是平凡的
- α是一个R的superkey
注意:
如果满足4NF则一定满足BCNF
10: Storage and File Structure
数据库的设计的要求:
- Data Storage
- Application Program Interface (SQL)
- Query/Insert/Delete/Update
- High Performance (Index, buffer manager, query processing/ Optimization)
- Concurrent Control并发控制
- Reliability可靠性非常重要
- Security安全性
Mini SQL Architecture:
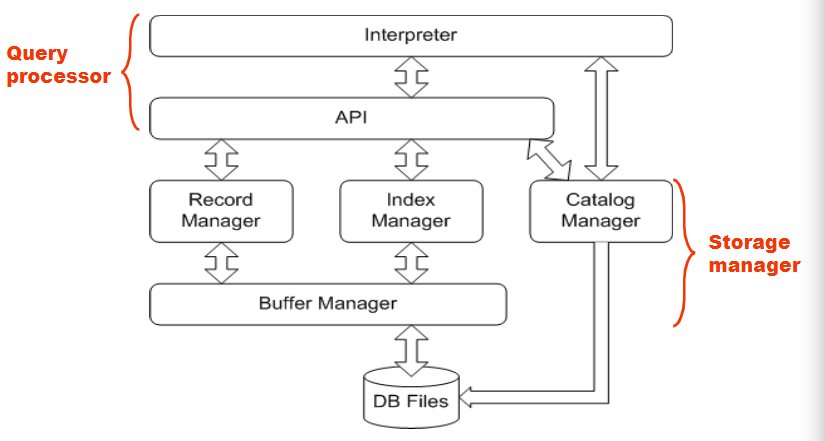
1. Overview of Physical Storage Media
1.1 分类
数据库的物理层面
Files、storage(.mdf,.ldf,.ora,.dbf)
储存媒体分类
- 数据库访问数据的速度speed
- 单位数据的花销cost
- 可靠程度Reliability:
- Data Loss on power failure or system crash
- Physical Failure of storage device(RAID)
1.2 Storage Hierarchy储存层次
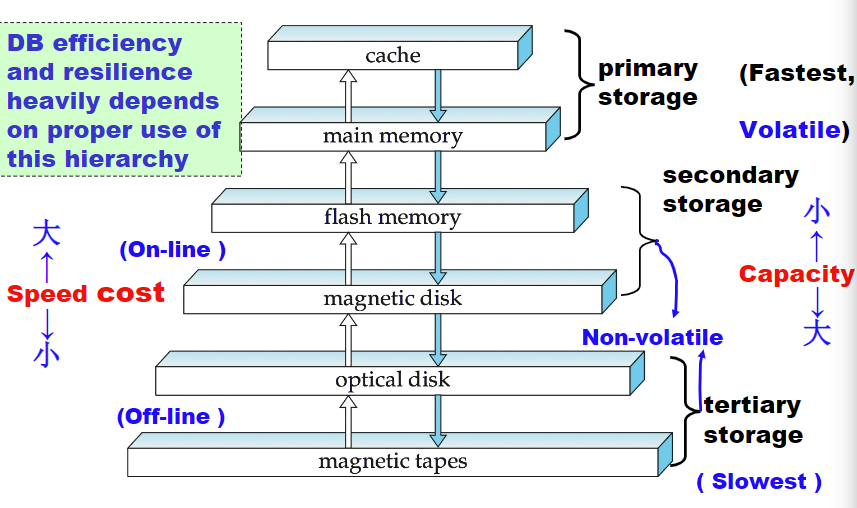
顶层读写块,但是花费大;底层读写速度慢,但是花费小
- 主存储(Primary Storage):最快的存储结构(cache、main memory),一般情况下关机重启后其中的数据就会没掉(易失性)
- 辅助存储器/联机储存器On-line(Secondary Storage):二级存储器(flash memory、magnetic disk磁盘),一般是与电脑主机联机的,CPU无法直接修改,关机重启后与数据都还在。
- 三级存储器/脱机存储器Off-line(Tertiary Storage):最底层的存储模块(optical disk、magnetic tapes),如磁带、光盘,比较便宜,并且一般可以脱离主机,需要使用时连接主机即可。
速度从快到慢:Cache ,Main-memory ,Flash memory,Magnetic-disk, Optical storage ,Tape storage
前两个是易失性的,后面四个非易失性
Cache:最快的也是最贵的,不稳定volatile,被电脑系统管理
Main Memory:很快(10-100ns),由于太贵了而导致太小了,有易失性
Flash Memory快闪存储器:读很快与main memory一致,但是写很慢,非易失性。写慢,删除更慢
Magnetic-disk:慢而便宜,非易失性,容量一般很大,速度>10毫秒
Optical Storage:光盘,只能读,难以改
Magnetic Tape:磁带

2. Magnetic Disk磁盘
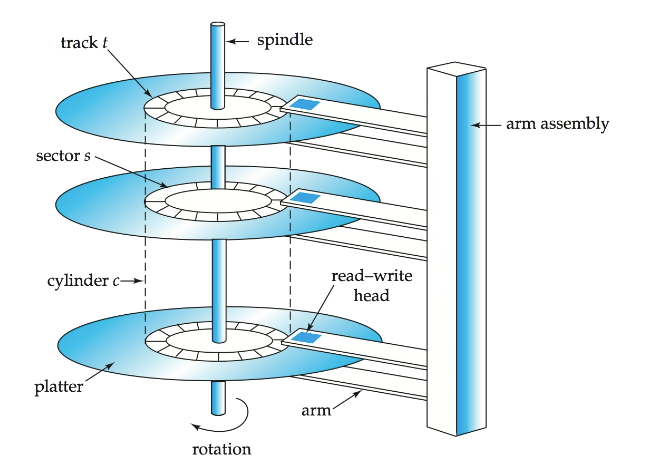
读写头
Disk arm 需要移动到到正确的Track上,这一段是寻道时间即找到数据所在Track的时间。
磁道Track
存数据的地方,一圈就是一个磁道,光盘会旋转从而找数据
2.1 Disk的性能衡量
Access time:
Seek time 寻道时间+Rotational latency 旋转等待时间
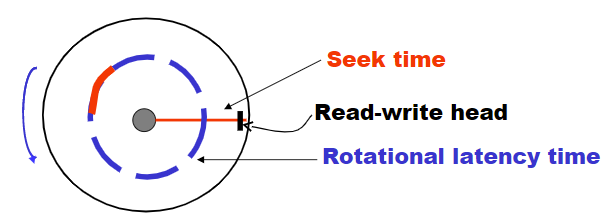
Data-transfer rate数据传输速率:
从磁盘检索数据或将数据存储到磁盘的速率。
Example
1
2
3
4
5
6
7
8IBM Deskstar 14GPX
3.5INCH,7200R/min
容量14.4G,含5张双面盘片,每张约3.35G
平均寻道时间9.1ms
相邻磁道寻道时间2.2ms
最大寻道时间 15.5ms
平均旋转等待时间 4.17ms
数据传输速率 13Mb/s磁盘的存取时间>10ms而内存的存取时间≈10ns,相差100万倍!
Mean time to failure 平均故障时间(MTTF)
体现可靠性,即寿命,一般为3-5年,数据会出错。
数据在磁盘上,也可能损坏的。
2.2 Block
数据库存储或者读取数据的最小单位
读数据是读取一个包含这个数据的一个Block而非只读这一个数据
数据以块的形式在磁盘和主存之间传输
大小范围从512字节到几千字节
- 更小的块:从磁盘传输更多的数据
- 更大的块:更多的空间浪费,因为部分填充的块
- 目前典型的块大小从4千字节到16千字节不等
2.3 Disk-arm-scheduling algorithm磁盘臂调度算法
电梯算法:
- 移动磁盘臂朝一个方向(从外到内追踪,反之亦然),处理下一个请求在那个方向,直到没有更多的请求在那个方向,然后反方向,重复。适用于运动方向一个维度的算法,尽量少的改变运动方向,知道所有的请求都要其改变方向
- Nonvolatile write buffers(非易失性写缓冲区)
- 通过立即将块写入非易失性RAM缓冲区来加速磁盘写操作
- 非易失性RAM:电池备份的RAM或闪存即使停电,数据也是安全的,并且在断电后仍可写入磁盘
- 当磁盘没有其他请求或请求等待一段时间后,控制器就会对磁盘进行写操作需要在继续之前安全地存储数据的
- 数据库操作可以在不等待数据写入磁盘的情况下继续进行,然后可以重新排序写入操作,以最小化磁盘臂移动
3. RAID
3.1 RAID
RAID:Redundant Arrays of Independent Disks (独立磁盘冗余阵列)
磁盘组织技术,管理大量磁盘,提供单个磁盘的视图
多盘并行使用,容量大,速度快
可靠性高,数据冗余存储,即使硬盘故障也能恢复
从两方面改善系统性能:
- 冗余–可靠性
- 并行–速度
3.2 Reliability
为了可靠性,要做出牺牲,即有效数据的容量降低
冗余:有数据的冗余,但是会有更高的可靠性
可以通过查看平均故障时间来衡量可靠性
比特级拆分:按比特作为最小的数据规模
块级拆分:按一个block作为最小的数据规模
3.3 RAID Levels
- RAID Level 0:
- 把所有的数据只存一次,没有数据冗余
- 优点:便宜,性能比较好
- 缺点:没有可靠性
- 适用范围:数据的可靠性无需保证,要求读写速度
- RAID Level 1:
- 数据完全存在两个地方
- 优点:可靠性高
- 缺点:昂贵,最佳的读写性能
RAID Levels 2:
Memory-Style error - correct - codes (ECC) with bit striping。
RAID Levels 3:
- 一个奇偶校验位就足以纠正错误,而不仅仅是检测错误,因为我们知道哪个磁盘出现了故障
- 写入数据时,也需要计算相应的奇偶校验位并写入校验位磁盘要恢复损坏磁盘中的数据,需要从其他磁盘(包括校验位磁盘)上计算位的异或
- 数据传输速度比单个磁盘快,但每秒I/O更少,因为每个磁盘都必须参与每个I/O。包含等级2。
- 只要不坏两块盘就可以恢复
RAID Levels 4:
- Block-Interleaved Parity
- 使用块级条带化,并在一个单独的磁盘上保留一个校验块,用于与N个其他磁盘相对应的块。
- 写数据块时,对应的校验位块也必须计算并写入校验盘为了找到一个损坏的块的值,从其他磁盘的相应块(包括奇偶校验块)中计算位的异或。
RAID Levels 5:
每个硬盘存有效数据也存异或的校验数据
并行度比level4更高
这么一来level2,level3,level4基本上全面被level5超越了
RAID Levels 6:
在level5基础上加上冗余
3.4 RAID Level的选择
只有在数据安全性不重要的情况下,才可以使用RAID 0,例如,数据可以从其他来源快速恢复
2和4不会使用,因为被3和5代替
级别3不再使用,因为比特条带化迫使单个块读取访问所有磁盘,浪费磁盘臂的移动,这是块条带化(级别5)避免的
6级很少使用,因为1级和5级为几乎所有应用程序提供了足够的安全性所以竞争只在1到5之间
所以我们一般使用1或者5!!!
4. Tertiary storage光盘和磁带
目前比较少使用
5. Storage Access
数据库文件在逻辑上被划分为称为块的固定长度的存储单元。
块是数据库系统中存储分配和数据传输的单元。
缓冲区:可用来存储磁盘块副本的主存部分。
数据库系统寻求最小化磁盘和内存之间的块传输数量。
- 为了减少磁盘访问的数量:在主存中保留尽可能多的块——Buffer。
- 但是缓冲区的大小是有限的。怎么办?
缓冲区管理器:负责分配缓冲区空间的子系统

Page是硬盘中的一个block在内存中的体现。
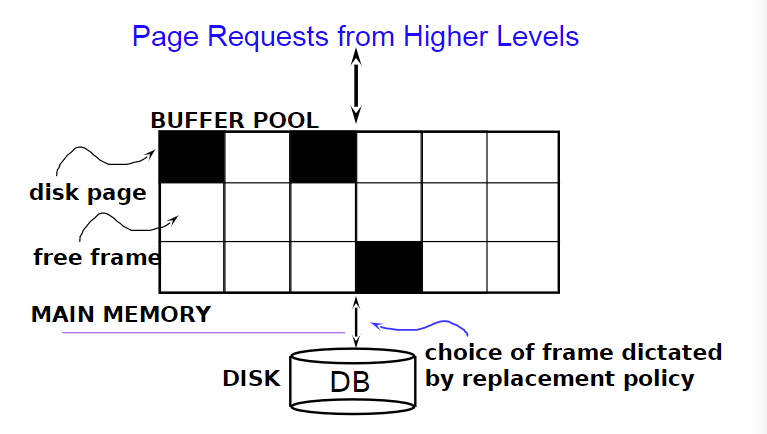
5.1 Buffer Manager
从硬盘中读取数据到内存
- block已经在buffer中了,则请求程序就会得到该数据块在主存中的地址
- block不在buffer中
- buffer没有满,直接放入缓冲区
- buffer满了,如果没有空闲空间,为新块腾出空间。要为新的Page分配空间
5.1.1 缓冲区丢弃策略
LRU:将冷数据丢弃
- 热数据:当前经常被读写的数据
- 冷数据:很少被读写的数据
缺点:刚用的块可能就不用了,此时是可以覆盖的,LRU不是最好的
MRU:将热数据丢弃
与LRU相反,不是绝对最优的策略
Pinned Block:把一些block钉住,无法丢弃出去,如正在被使用的块钉住
Toss-immediate strategy:用了直接丢弃
Forced output of blocks:块的请求者必须unpin,并表明页面是否被修改。
统计正在使用的事务量:某个数据被使用的数量,pin count=0的时候丢弃
6. File Organization
- database由文件构成
- 文件由一些列record构成
- record有一系列的fields
- 两种record方式:
- 定长的record
- 变长的record
6.1 定长的Records
优点:
- 方法简单
缺点:
- 由于定长而浪费空间
删除:
空着这一行,可能对null有要求
把下面行的数据上移一行,移动复杂
最后一行搬到这一行,但是顺序被打乱
空行进行标记,使用一个List来连接空行
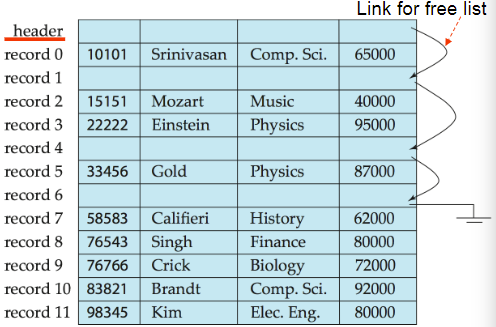
优点:便于插入,更加高效
6.2 变长的Records
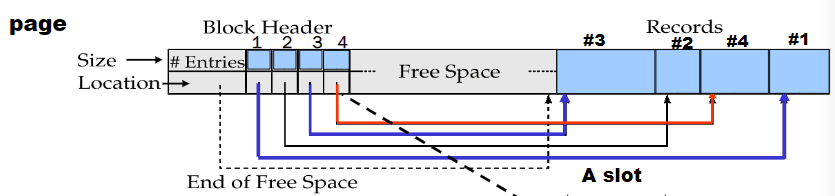
Slotted page header包含:
- 记录条目的数量
- 块中空闲空间的结束
- 每个记录的位置和大小
页内无碎块,删除时页内移动记录
7. Organization of Records in Files
Heap file
Sequential file顺序文件
按照一定的顺序排列文件
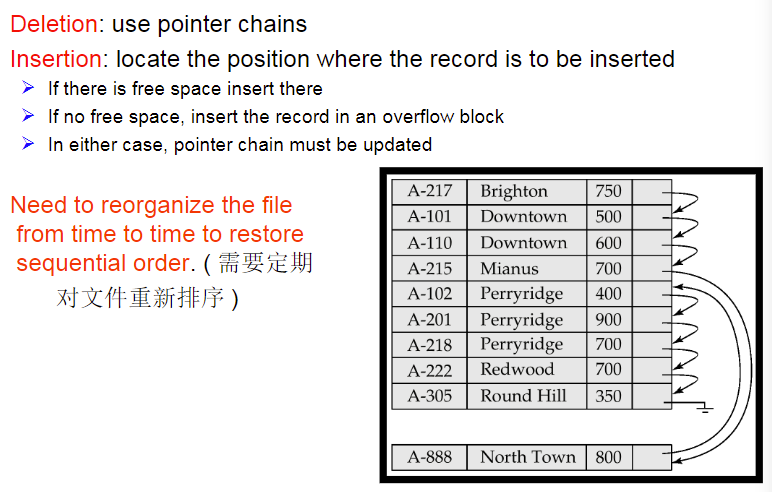
Hashing file散列文件
Clustering file organization聚集文件组织
按不同属性的划分,可以进行聚集,比如
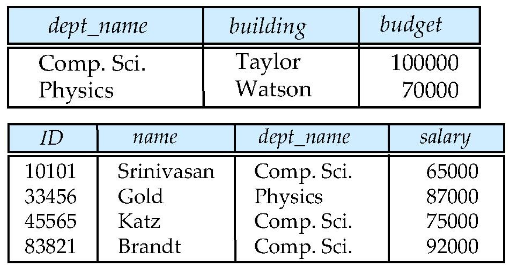
可以聚集为:
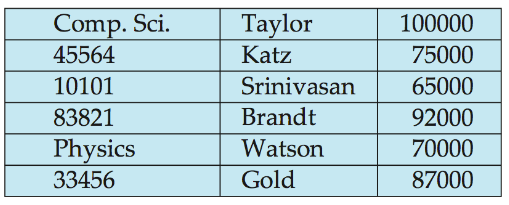
如此一来,查询Comp.Sci.只需要导入某个块,而不是把整个instructor的表的块全部导入而是仅仅导入Comp.sci.下的数据。
为了保证Comp.sci.和Physics这个dept表也能正常查询,我们可以使用链表把这两行连起来。
8. Data-Dictionary Storage
数据字典是元数据:描述了数据(表)的数据,如
- 关系(表)的信息
- 用户的信息
- 统计信息
- 物理层面信息,数据存在哪里
- indices目录的信息
也是使用表的方式存储!是一类特殊的表。
11:Indexing and Hashing
1. Basic Concepts
索引:对于查找有帮助
包含:Search-Key , Pointer
分类:
顺序索引
根据一定的顺序存储key
散列索引
使用hash函数确定key存放的位置
Access time
查询效率变高
Insertion time
插入时间,写的方面的时间变大
Deletion time
删除时间,写的方面的时间变大
Space overhead
2. Ordered Indices
在ordered index中,索引的顺序和数据的search key的排列顺序一样
主索引(primary index)
- 索引值的search key和顺序排序数据的search key一致
- 其他的是辅助索引
- 主索引通常是主码,但并非一定是主码
稠密索引文件Dense Index Files
- 数据里面出现的每一个search key在索引中都出现了,不要求一一对应,但是要全部出现。
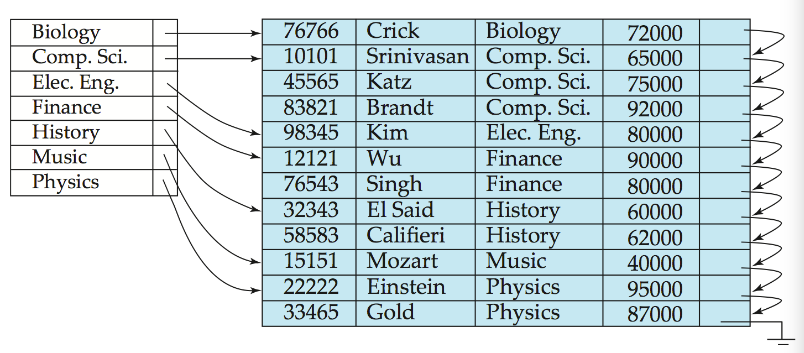
- 稠密索引且为主索引
稀疏索引文件Sparse Index Files
索引只包含了部分的search key
稀疏索引的搜索方法:类似于二分查找找区间即可
优点:空间占用少,可以在内存中使用
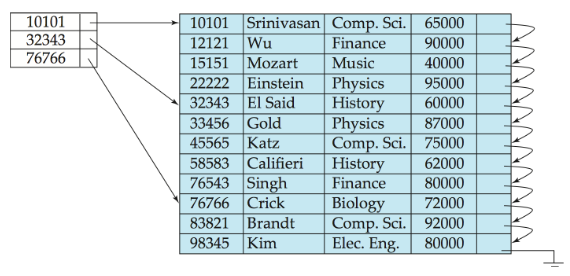
稀疏索引且为主索引
Good tradeoff:
- 稠密索引的速度并没有比稀疏索引快
- 硬盘读入内存的最小单位为一个block,一个block中可能有多个数据记录,每块中的最小的搜索键值放在索引项中。
- 我们找数据只要找到数据所在的block,找数据时通过比较就可以找到数据的存放block
Sparse index只用于顺序文件,而dense index可以用于顺序文件和非顺序文件
二级索引/辅助索引 Secondary Indices
- 二级索引/辅助索引,一般采用稠密索引
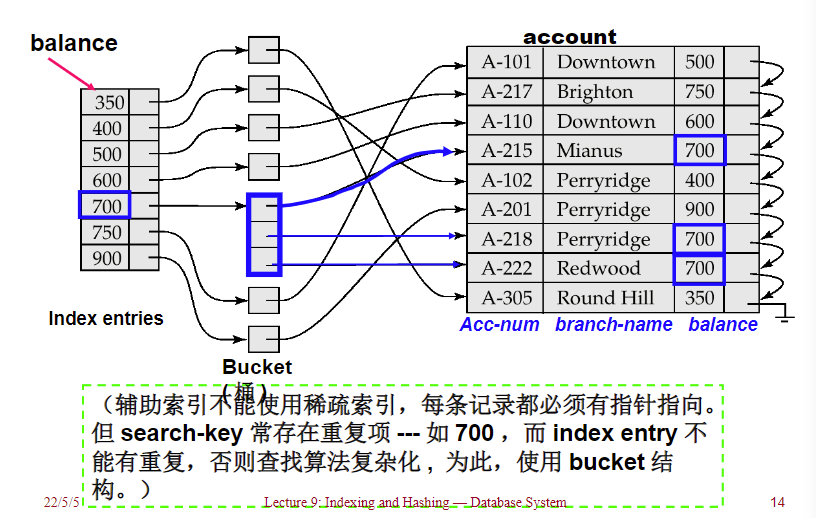
- 如上表,balance为700的search key,此时我们为了通过这个索引要找到数据,这个二级索引必须要是稠密索引,不然的话会找不到。
Multilevel Index
主索引可能会很大而不能装入内存,因此我们可以建立一个主索引的稀疏索引,即索引的索引。
找一个数据先通过外索引(outer index)找到内索引(inner index)即主索引,再查找数据。
如果outer index仍然很大,那可以继续扩展,可以推广到任意多层
Index Update:Deletion
step1:系统找到一个数据文件,删除record
step2:
稠密索引:
- 唯一性:直接删除
- 非唯一:删的是二级索引的第一条,把二级索引的第一条指向后一个,删掉的不是第一个那么不用改变
稀疏索引:
- 稀疏索引如果已删除记录的搜索键值没有出现在索引中,则对索引不做任何操作。
- 否则,如果索引文件中存在该搜索键的索引条目,则通过将该条目替换为数据文件中的下一个搜索键值(按搜索键的顺序)来删除该条目。
- 如果下一个搜索键值已经有一个索引项,那么该索引项将被删除,而不是被替换。
Index Update:Insertion
- 稠密索引:
- 搜索键值没有出现在索引中,则插入一个带有搜索键值的索引条目
- 否则,如果使用多指针,则添加一个指向新记录的指针(在索引项中)
- 否则,与索引项无关
- 稀疏索引:
- (假设每个块都有一个索引条目)如果创建了一个新块,将新块中出现的第一个搜索键值插入索引中。
- 如果新记录的块中搜索键值最小,则更新索引项。
- 否则没有变化
- 稠密索引:
二级索引的新增与删除
- 必须是主索引,所以是一一对应的,直接根据以上的规则进行修改
3. B+树
B-tree索引是索引顺序文件的替代方法。
索引顺序文件的缺点
- 随着文件的增长,性能下降,因为创建了许多溢出块。
- 需要定期重组整个文件。
B-tree索引文件的优点
在面对插入和删除时,使用较小的本地更改自动重新组织自身。
不需要对整个文件进行重组来保持性能。(次要)B-树的缺点:额外的插入和删除开销;空间开销。
B+-tree的优点大于缺点: B*-树被广泛使用
B+树的特点:
M阶的B+树定义:
- 根节点是叶节点或者根节点有2~M个儿子
- 根之外的非叶节点有$[\frac{M}{2}]$
M个儿子,每个叶节点有$[\frac{M}{2}]$M个子节点(NULL) - 叶子节点的Key值在$\lceil(n-1)/2 \rceil 和n-1$之间
- B+树的儿子指的是节点指向的新节点而非节点内的数据
- 每个节点的 key数是子节点数-1,画图的时候key分布在指向两个儿子的箭头之间
- key值的确定方法:等于key右边第一个指针对应子节点的最左边的值
- 所有叶节点的深度相同
- B+ Tree of Order 4 也称为2-3-4树,order 3 的称为2-3树
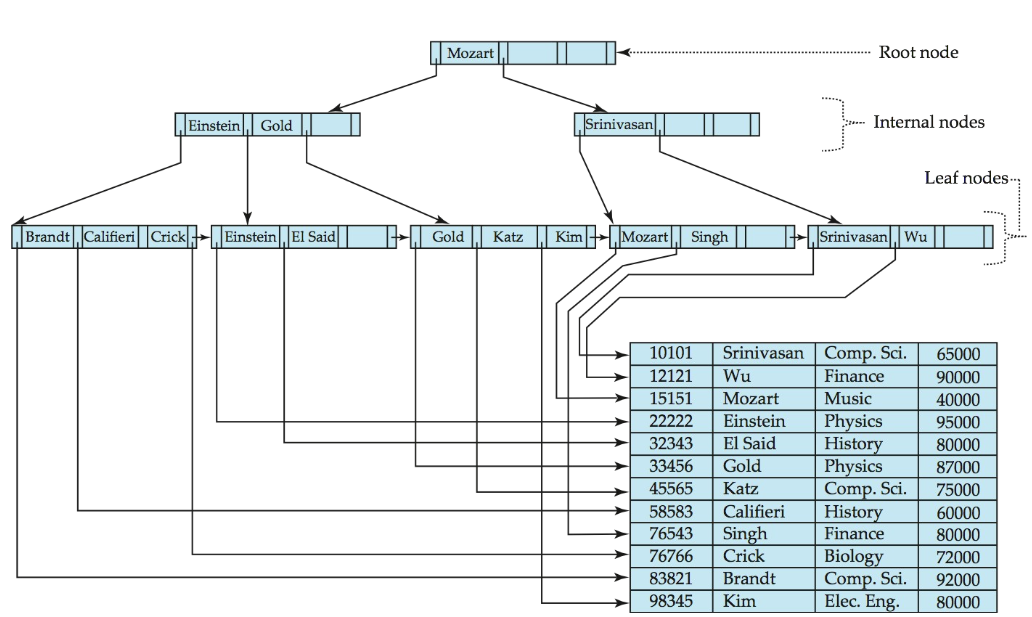
B+树的结点的结构:

- 由指向孩子的指针和键值组成
- 键值是按顺序排列的
- 通常一个节点对应一个Block,从而确定B+树的阶数
B+树的查找
- N阶B+树,K个key,树高最高为$\lceil log_{\lceil n/2\rceil}(K)\rceil$
- 对查询的效率有很大的提高
B+树的插入
找到这个数据应该所处的叶节点
插入,如果key的个数超过了M-1,那么分裂为2个有$[\frac{M-1}{2}]$的key值的节点,依此向上递归。
1
2
3
4
5
6
7
8
9
10
11
12
13Btree Insert ( ElementType X, Btree T )
{
Search from root to leaf for X and find the proper leaf node;
Insert X;
while ( this node has M+1 keys ) {
split it into 2 nodes with [(M+1)/2] and [(M+1)/2] keys,
respectively;
if (this node is the root)
create a new root with two children;
check its parent;
}
}
//算法的描述:找到合适的位置先插入,如果叶节点的keys数量超过了M,则分裂成两个,然后向上继续合并和拆分
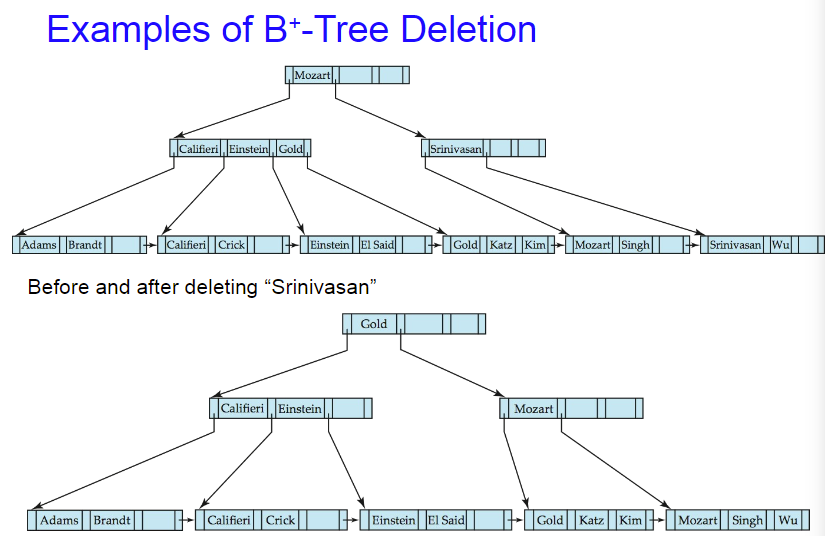
B+树的删除操作
找到这个节点
删去后小于$\lceil\frac{M}{2} \rceil$个子节点(NULL),则Merge一下,Merge完可能太多了再拆分掉,查看父亲的儿子个数继续向上递归。
4. B树Index Files
- 其他与B+树一样,但是,B+树只有在叶子节点才能查找数据
- B树在非叶子节点也可以找,找到一样的Key直接找Value
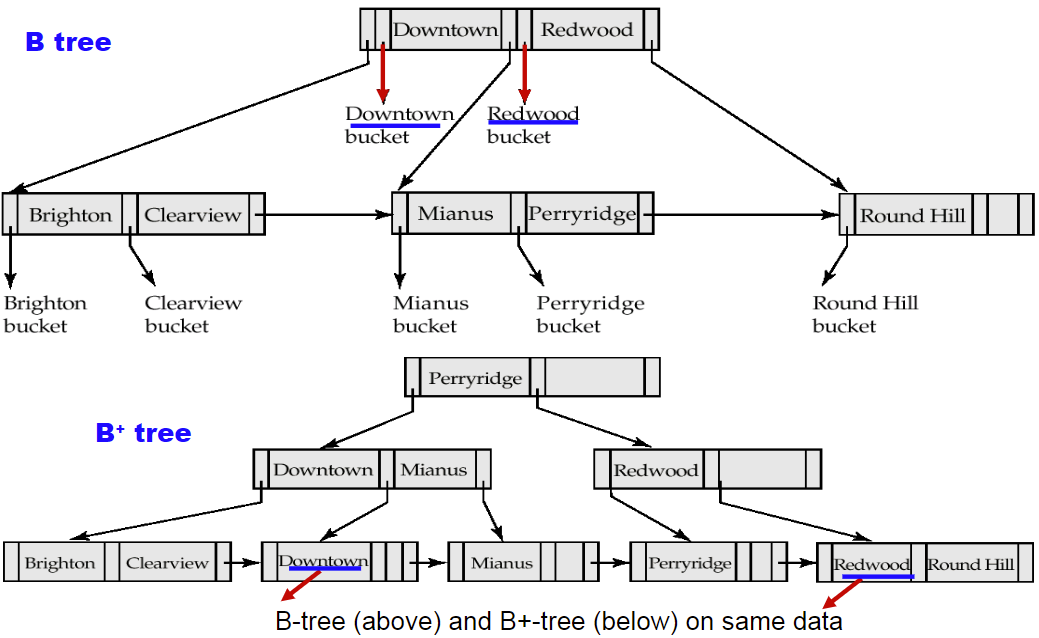
- B树的查找效率比B+树高
- 为什么还用B+树:
- b -树指数的优点:
- 可能比相应的B+-Tree使用更少的树节点(因为重复)。
- 有时可能在到达叶节点之前找到搜索键值。
- b树索引的缺点:
- 在所有搜索键值中,只有一小部分在早期被发现
- 非叶节点更大,因此减少了扇出
- 因此,B树通常比相应的B+树有更大的深度
- 插入和删除比B树更复杂实现比B+树更难。
- b -树指数的优点:
5. Static Hashing 静态哈希
- 桶bucket是包含一条或多条记录的存储单元(桶通常是磁盘块)。
- 在哈希文件组织中,我们使用哈希函数直接从记录的搜索键值获得记录桶。
- 哈希函数h是从所有搜索键值K的集合到所有桶地址B的集合的函数。
- 哈希函数用于定位记录的访问、插入和删除。
- 具有不同搜索键值的记录可以映射到相同的bucket;因此,必须依次搜索整个桶来定位一条记录。
Hash索引,根据属性设计哈希函数,进行计算计算出这个属性对应的数据应该存放的位置bucket。当桶overflow则用指针指向新的位置
6. Write-optimized Indices
LSM树索引
面向写的优化的一颗树:只考虑插入和查询
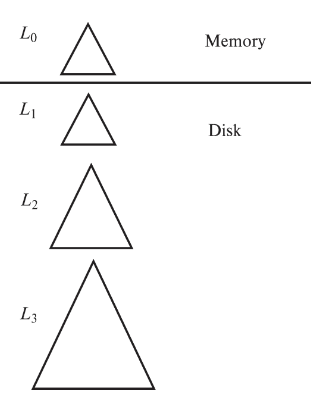
数据插入时线插入内存中的L0树,当L0树满了,将L0存到磁盘上作为L1,继续输入L0,满了之后L0和L1合成为一个L2存在磁盘,如是反复,就像二进制的加法一样,但是这里的合并要按顺序写入
LSM的优点:
- 插入只需要在内存中完成,很快
- Leaves是满的,避免内存浪费
- 减少IO操作
LSM的缺点:
- 查询要查询很多颗树
- 先查内存、再查Level1、Level2…
- 多次复制每个级别的完整内容
Stepped-merge 索引
- LSM树的变体,每层有多棵树
- 与LSM树相比,减少了写开销
- 但是查询的开销更大
- Bloom过滤器,以避免在大多数树中查找
Buffer Tree
- LSM树的替代方案
- 关键思想:
- B+tree的每个内部节点都有一个缓冲区来存储插入
- 当缓冲区满时,插入被移动到较低的级别
- 对于一个大的缓冲区,每当每条记录的I/O相应减少时,许多记录都会被移动到较低的级别
- 好处
- 更少的查询开销
- 可用于任何树索引结构
- 用于PostgreSQL广义搜索树(GiST)、
- 索引缺点
- 比LSM树有更多的随机I/O
7. Bitmap Indices
是用于多值查询的,因为对于域少的属性,查询结果会很多
位图索引是一种特殊类型的索引,用于对多个键进行高效查询关系中的
记录假定从0开始按顺序编号给定一个数字n,检索记录n必须很容易,特别是当记录是固定大小时
适用于具有相对较少的不同值的属性例如,性别,国家,州,例如收入水平(收入分成少量的水平,如0-9999,10000-19999,20000-50000,50000-无限)
位图就是位的数组
将所有的对象的属性放在一个属性的位图中,如:
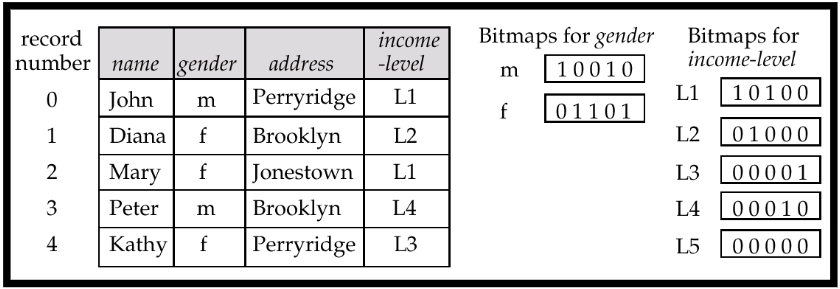
- 如m的位图中第一个和第三个是男的
- L1中的第一位和第三位是收入在L1的
- 要多值查询直接可以进行一个操作即可。
- 如与、或、非
注意只适用于取值范围小的情况
12:Query Processing 查询处理
通常来说,查询语句是最重要的。
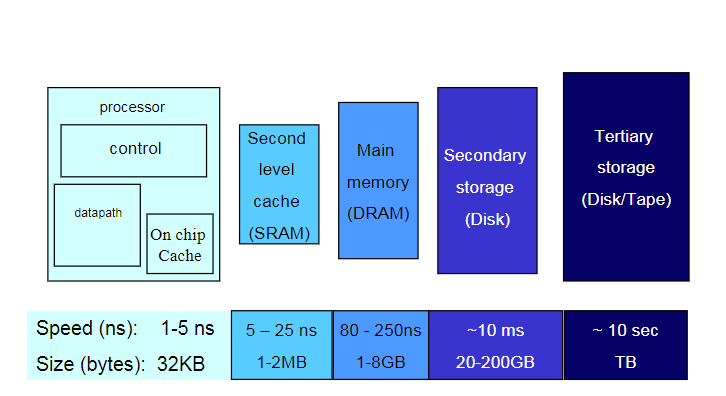
- Levels of Memory Hierarchy
1. Overview
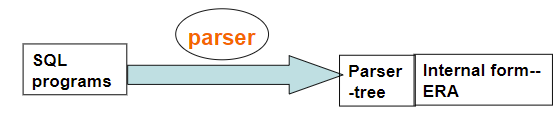
Parsing and translation
Optimization
Evaluation
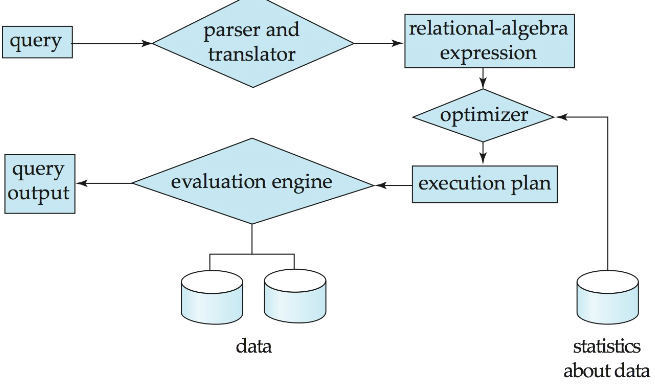
1.1 Paring and translation
分析语法、关系,并且进行翻译
1.2 Evaluation
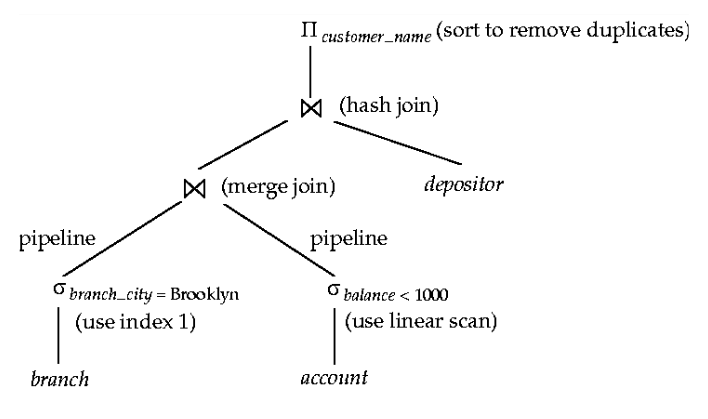
生成查询计划,查询计划是定义了那些算法在哪个步骤中需要使用,操作如何执行实现等。
1.3 Optimization
2. Measures of Query Cost
- 有许许多多的查询方法,我们要知道这些算法的效率
- time Cost = Disk access + CPU + network communication
- 在这里我们只讨论Disk access的时间
2.1 硬盘的时间
- Seek 时间:磁头的寻道时间
- 传输时间:write和read的时间
我们可以将其抽象为:
- seek的操作的次数
- transfer(write、read)的block的个数
$t_s-time\ for\ seek$
$t_T-time\ to\ transfer\ one\ block$
b次block transfers和s次的寻找
- $bt_T+St_s$
3. Selection Operation
线性搜索:
seek只需要一次,只需要找到第一个block向后找
设有$b_r$块,平均的寻找时间是br/2则
$Cost=\frac{b_r}{2}\ block transfer+1\ seek$
$Cost=\frac{b_r}{2}t_T+t_s$
二分搜索:
根据主键查找,主键是顺序储存的。
$Cost=\lceil log_2(b_r)\rceil *block\ transfer+\lceil log_2(b_r)\rceil *seek$
$Cost=\lceil log_2(b_r)\rceil(t_s+t_T)$
block transfer的次数$=\lceil log_2(b_r)\rceil+\lceil \frac{sc(A,r)}{f_r}\rceil-1$
$sc(A,r)$是满足条件的记录数
$f_r$是每个block的记录数
3.1 树索引
A3(primary index,equality on key单个)
在树上找,那就是一次seek一个block(node)
有h+1次的seek和transfer
$Cost=(h_i+1)*(t_T+t_S)$
A4(primary key,equality on nonkey有多个结果)
$Cost=h_i(t_T+t_S)+t_S+t_T*b$
$b=\lceil \frac{sc(A,r)}{f_r}\rceil$
A5(secondary index,equality on nonkey)
这个search-key是候选码:
找到的有且只有一个,与primary index是一样的
$Cost=(h_i+1)*(t_T+t_S)$
不是候选码:
满足结果的记录数有n个,每一个都可能在不同的block中,之多有n个block中
$$Cost=(h_i+n)*(t_T+t_S)$$
3.2 范围检索
A6(primary key ,comparison)基于主索引的比较
对于要找大于等于V的,找到这个等于V的位置即可,一直向后找,小于等于的就是找到前面的。
A7(secondary index,comparison)基于辅助索引的比较
找到V的位置,查询其叶子节点。
3.3 And的查找
A8(conjunctive selection using one index)
只使用一个索引,先用代价最小的索引查一次,再在结果集中继续查询。
A9(conjunctive selection using composite index)
多值查询,果可用,使用适当的复合(多键)索引。
A10(conjunctive selection by intersection of identifiers)
需要带记录指针的索引。对每个条件使用相应的索引,并取所有获得的记录指针集的交集。然后从文件中获取记录如果某些条件没有适当的索引,则在内存中应用test。
- 对于或,用线性扫描也是可以的
- 对于非,用线性扫描,要预估结果的规模
4. Sort
归并排序,在每一个小的block先排好序,再进行merge合成大的排序
Example:
24,19,31 | 33,14,16 | 16,21,3 | 2,7,14
先块内排序:
19,24,31 | 14,16,33 | 3,16,21 | 2,7,14
再进行merge:
14,16,19,24,31,33 | 2,3,7,14,16,21
Merge的次数:$\lceil log_{M-1}(b_r/M)\rceil$其中M为Block的大小,b为数据的个数
Transfer的次数:$b_r(2\lceil log_{M-1}(b_r/M)\rceil+1)$两读一写
seek的次数:每个block要读和写$2\lceil b_r/M\rceil$,设buffer size为$b_b$,每次可以取出$b_b$个数据,即为$2\lceil b_r/M\rceil+\lceil b_r/b_b\rceil(2\lceil log_{M-1}(b_r/M)\rceil-1)$
5. Join Operation
Example:customer.n=10000, depositor.n=5000;customer.b=400,depositor.b=100
5.1 两个for循环进行连接
1 | for each tuple tr in r do begin |
$n_r*b_s+b_r$为block的transfers
外面的r只需要读br次,内部的s再每一个r的元素中要读bs次,即nr*bs次
$n_r+b_r$为seeks
5.2 四个for循环
1 | for each block Br of r do begin |
这个算法全面比第一个好。
有$b_r*bs+b+r$的block transfer
有$2*b_r$的seeks
5.3 Indexed Nested-Loop Join
有一个表有B+树索引,把一张表的一个block读进来,对于block中的一行,再有B+树索引的表中查找这个值
$Cost=b_r(t_T+t_S)+n_r*C$
C是操作的cost
5.4 Sort Merge-Join
首先确保两个排好顺序,这样已经遍历过的就无需回退
那么每一个block只读入了一次
$b_r+b_s$次block transfer
$b_r/b_b+b_s/b_b$次的seeks
还要加上排序的代价。
5.5 Hash Join
设定一个hash函数,r映射到p1,s映射到p2,r要等于s,那么r和s的hash值一定相等。在p1-p2中找可以形成配对的组合
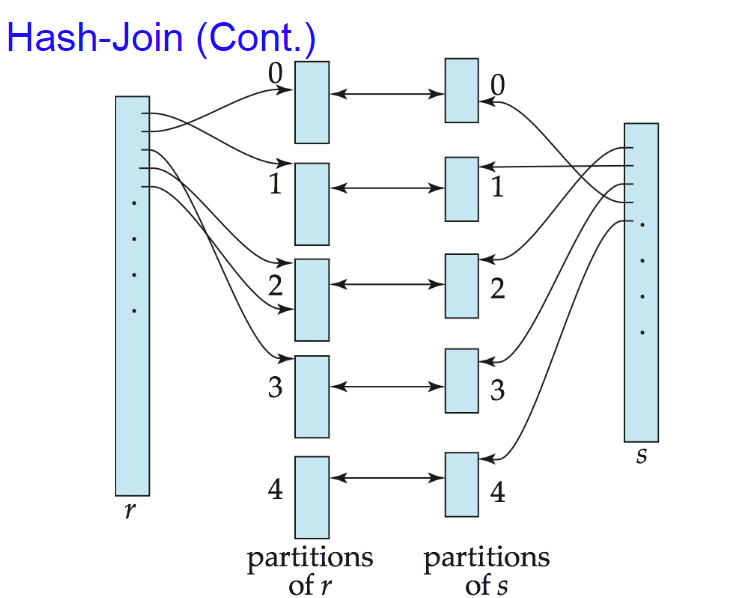
两个大表变成许多小表的join,想要join成功只有在同一个partition中才可能相等。即可以把大表的连接做成小表的连接。
block transfer:首先假设r有br块,s有bs块,把r表每一个都读进来计算hash值写回去,即2br,s也一样,2bs,在真正的join中再读进来一次br+bs。在计算出来的hash值中,要都进来一次写出去一次,在后续的join中也是读一次写一次。即为$3(b_r+b_s)+4n_h$。nh是分区的个数。
seek:为了计算hash,读入br/bb+bs/bb,在真正的join时也是如此,hash值也是每次读写nh个分区的block即为。$2(b_r/b_b+b_s/b_b)+2n_h$
6. Evaluation of Expressions
6.1 Materialization 实体化
将计算的expression的结果放入磁盘
即一边计算一边写硬盘,除非计算的速度远大于写的速度。
6.2 Pipeline 流水线
Example

(1)
20000/25=800 block
45000/30=1500 block
800*1500+800 = 1200800次transfer
seek:800*2=1600次
(2)
T2取一个tuple,每一个tuple做一次对T1的从顶到叶的查询
T2每一个block都要读进来
45000*(3+1)+1500 transfer
1500 seek
13:Query Optimization
1. Introduction
查询计划:要制定查询计划,有了查询计划数据库可以直接调用函数进行查询。
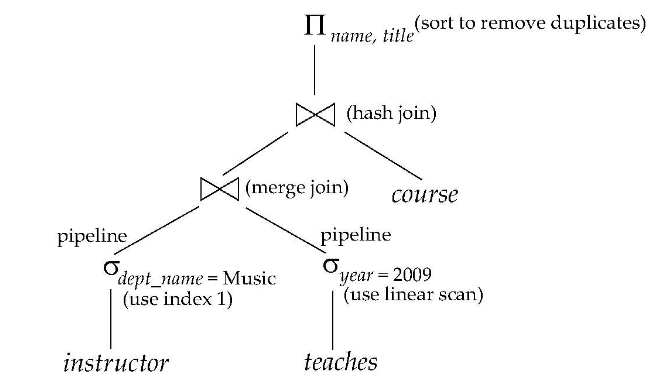
- 查询计划有说明计算方法,储存方式等
2. Transformation of Relational Expressions
如果两个关系代数表达式在每个合法数据库实例上生成相同的元组集,则这两个表达式被认为是等价的。
- 元组的顺序无关
- 我们不关心它们是否在违反完整性约束的数据库上生成不同的结果
在SQL中,输入和输出是元组的多集
- 如果关系代数的多集版本中的两个表达式在每个合法数据库实例上生成相同的元组多集,则这两个表达式被认为是等价的。
等价规则认为两种形式的表达式是等价的可以用第二种形式替换第一种形式的表达式吗
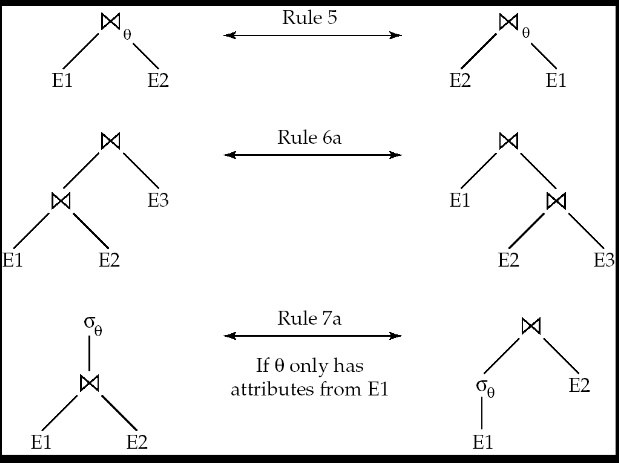
2.1 等价转化规则
$\sigma_{θ_1\andθ_2}(E)=\sigma_{θ_1}(\sigma_{θ_2}(E))$
$\sigma_{θ_1}(\sigma_{θ_2}(E))=\sigma_{θ_2}(\sigma_{θ_1}(E))$
$\Pi_{L_1}(\Pi_{L_2}…(\Pi_{L_i}(E)))=\Pi_{L_1}(E)$
$\sigma_θ(E_1×E_2)=E_1\Join _{θ}E_2$
$\sigma _{θ_1}(E_1\Join _{θ_2}E_2)=E_1\Join _{θ_1\andθ_2}E_2$
$E_1\Join _{θ}E_2=E_2\Join _{θ}E_1$
$E_1\Join _{θ_1}(E_2\Join _{θ_2}E_3)=(E_1\Join _{θ_1}E_2)\Join _{θ_2}E_3$
$E_1\Join _{θ_1}(E_2\Join _{θ_2\andθ_3}E_3)=(E_1\Join _{θ_1\and θ_3}E_2)\Join _{θ_2}E_3$
注意先选再连接比先连接再选要好,因为连接的开销很大。先投影也是这个原理
如果θ0只对E1的属性有要求$\sigma _{θ_0}(E_1\Join {θ}E_2)=\sigma{θ_0}(E_1)\Join _{θ}E_2$
θ1只在E1中,θ2只在E2中
$\sigma _{θ_1\andθ_2}(E_1\Join {θ}E_2)=\sigma{θ_1}(E_1)\Join {θ}\sigma{θ_2}(E_2)$

在查询树中,我们要把选择操作向叶子进行优化,即让选择投影先做,连接后做。
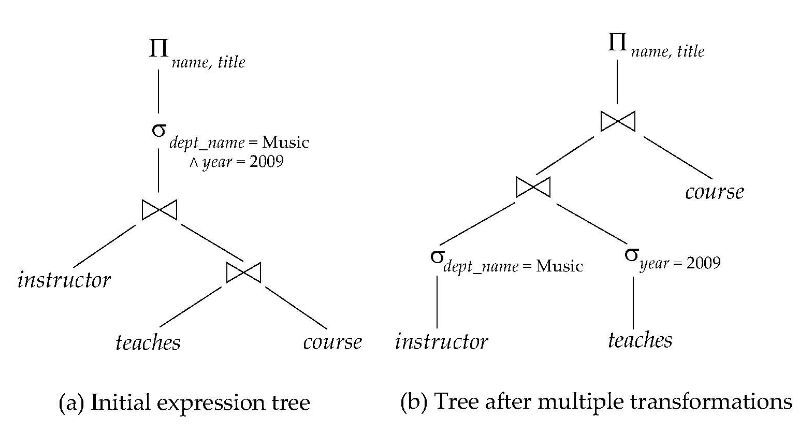
在连接方面,如果有$r_1\Join r_2\Join r_3$
如果$r_1\Join r_2$和$r_2\Join r_3$有大小关系已知,优先做结果小的连接。
3. Statistics for Cost Estimation

3.1 Selection Size Estimation
$\sigma_{A=V}(r)$
- $n_r/V(A,r)$平均满足selection的records数量
- Equality condition on a key attribute:size estimate = 1
$\sigma_{A≤V}(r)$
- 设c是预估的满足条件的tuples
- v<min(A,r):c=0,不用查了查不到
- $c=n_r\frac{v-min(A,r)}{max(A,r)-min(A,r)}$
Complex Selections

3.2 Estimation of the size of joins


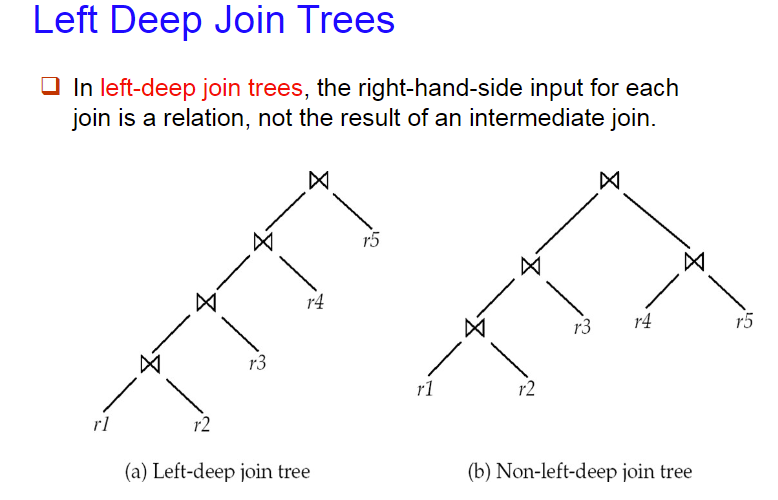
4. Dynamic Programming for Choosing Evaluation Plans 动态规划选择评估策略
 Left Deep Join Tree:有利于流水线
Left Deep Join Tree:有利于流水线
14:Transactions事务
1. 事务的概念
- 并发问题:多用户或者多进程
- 故障的处理:数据库故障了如何回复数据等
事务是一堆的sql语句,但是事务执行完毕后只有两个出口:提交(commit)和回滚(rollback),但是要保证一致性,要符合四个特性ACID
- Atomicity原子性:sql代码是不可分割的,要么完全执行要么都不执行
- Consistency一致性:执行的前后保证结果一致
- Isolation隔离性:面向并发的,其他的事务与当前事务无关
- Durability持久性:能够长久正常运行
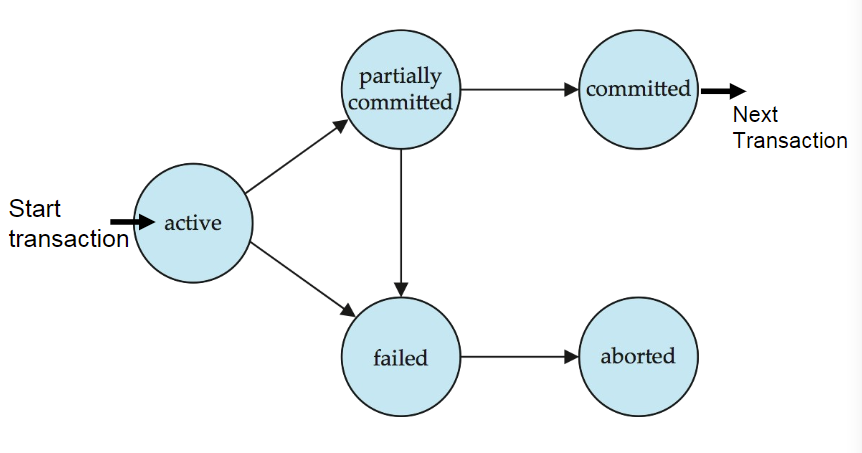
2. Transaction State
Active
- the initial state; the transaction stays in this state while it is executing
Partially committed
- after the final statement has been executed.(此时要输出的结果数据可能还在内存buffer中)
Failed
- after the discovery that normal execution can no longer proceed.
Aborted
– after the transaction has been rolled back and the database restored to its state prior to the start of the transaction. Two options after it has been aborted
Restart the transaction
Can be done only if no internal logical error
Kill the transaction
Committed
- – after successful completion.
3. 原子性和持久性
影子拷贝
新开一个数据,从老数据那里复制,在这个数据改,改完把指针指向这个新的数据
4. Concurrent Executions
保证并发调度的一致性
5. Serializability
并发事务的可能互相影响的时间是在硬盘上的时间。
其他在内存里的事务操作都不会影响
即Read和Write操作

6. 可恢复性
一个事件可能需要回滚,把所有的操作重新恢复
但是可能会有不可恢复的操作出现

不可恢复的调度
- 这种调度是不被允许的
- 当一个事务受另一个事务的影响,在另一个事务提交之前这个事务不可以提交
级联回滚
- 一个事务的回滚影响后面事务的回滚
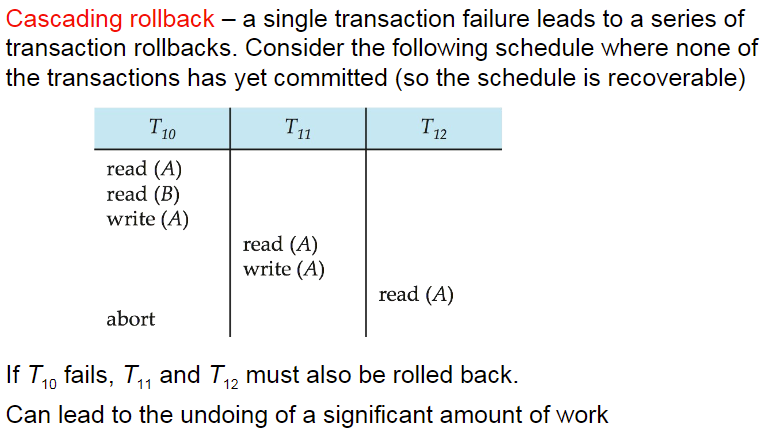
7. 事务的独立性
两个事件之间加箭头:A→B,在AB和B冲突,且A的操作先执行,如果有一个循环则说明不可变成串行化的
Lecture 13:Concurrency Control
1. Lock-Based Protocols
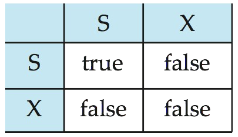
X锁:读写的锁
S锁:只读的锁
锁的协议:
- 读之前要获得S锁
- 写之前要获得X锁
- 可能存在死锁,如图:

Starvation 饿死
设T1拿了A的S锁,
T2想要写A,试图申请A的X锁,但是申请不到
T1释放S之前,T3来了要S(A),一直这样持续下去
T2一直在等待S的释放(饿死)
两阶段加锁协议
保证了冲突可串行化
在某个点之前只加锁,不释放锁,在这个点后只释放锁,不加锁。
- Growing Phase
- Shrinking Phase
证明:
假设调度有n个事务,T1、T2…Tn,这些事务的加锁都符合两阶段加锁,且LockPoint递增,假设是不可串行化的,变成有向图会有一个循环。设T1→T2→T1,T2拿到锁,T1应该已经释放了,则说明,T1的LP<T2的LP,同理矛盾了
- 能够保证两阶段加锁则一定可以串行化
- 但是可串行化不一定就保证了两阶段加锁协议
优化:
- 阶段一:获得锁,或者S升级为X
- 阶段二:释放锁,或者将X降级为S


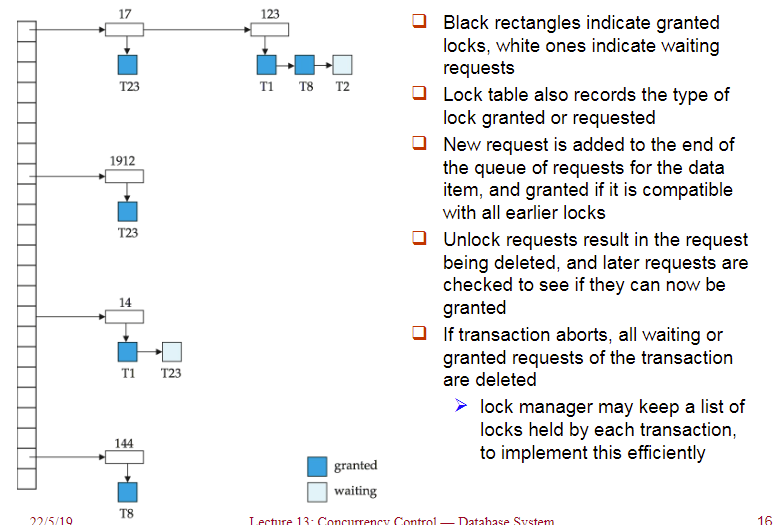
2. Lock Table 锁表
3. Graph-Based Protocols
Review :
- 并发调度和一个串行调度的结果是一样的,那么肯定是冲突可串行化的
- 遵守两阶段加锁协议,一定是冲突可串行化的,反过来不对
Tree Protocol
树加锁,事务的第一次加锁没有限制,只要锁没有被拿即可
解锁可以在任何时候
要获得一个数据Q的锁,必须要Q的父亲的锁
优点:
- 冲突可串行化
- 避免死锁
缺点:
- 要拿一些没有必要的锁
- 并发度不高
4. 基于时间戳的协议Timestamp-Based Protocol
每一个事务都有一个时间戳TS:定义为开始执行的时间点
每一个被读写的数据有时间戳:
- 写时间戳:最后一个写操作事务的TS
- 读时间戳:最后一个读操作事务的TS
4.1 读Read(Q)
当TS(Ti)<=W-timestamp(Q),那么说明Ti事务执行时,有其他事务写Q,那么就拒绝读,Ti回滚
当TS(Ti)>=W-timestamp(Q),那么说明Ti事务执行前,有其他事务写Q,那么不会影响Ti,读操作执行,R-timestamp(Q)=max{R-timestamp(Q),TS(Ti)}
4.2 写Write(Q)
当TS(Ti)<R-timestamp(Q),那么说明Ti事务执行时,有其他事务读Q,那么就要读Q之前的值,Ti的写操作要被拒绝,Ti回滚
当TS(Ti)<W-timestamp(Q),那么说明Ti事务执行时,有其他事务写Q,写操作被拒绝Ti回滚
其他情况,写操作被执行,W-timestamp(Q)=TS(Ti)
5. 意向锁Intention Lock Modes
- IS共享型意向锁:后代至少有一个有S锁,并不知道是哪个
- IX排他型意向锁:后代至少一个有X锁
- SIX共享排他型意向锁:后代全部被加了S锁,至少一个被加上了X锁
- SIX=S+IX
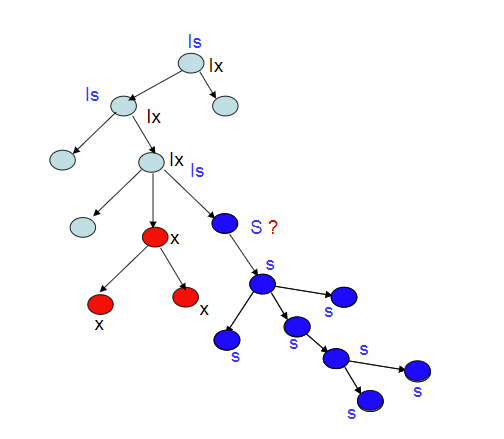
加锁的允许性:
- 可以直接从根开始判断是否可以加锁
- 加锁矩阵
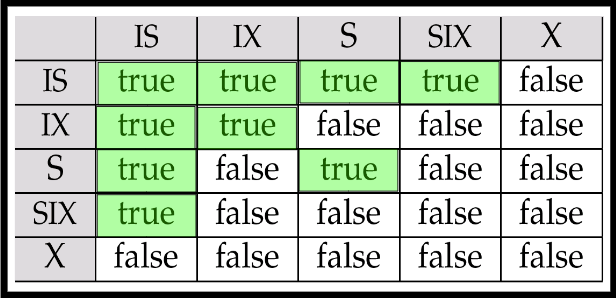
- 只要可能加得上就可以通过,在下面继续判断,如加IS锁时,一个节点是IX锁,那么有可能这个节点的子节点有一个没有锁的就可以加IS锁,就通过了。
加锁自上而下
解锁自下而上
6. Deadlock Handling
死锁如何解决?
1 | T1: Write(X),Write(Y) |

死锁预防协议确保系统永远不会进入死锁状态。
一些预防策略:
1)要求每个事务在开始执行之前锁定它的所有数据项(预声明)——保守2PL。(全部或没有被锁定)
- 缺点:并发性差,难以预测
2)对所有数据项进行部分排序,要求事务只能按顺序锁定数据项(基于图的协议)。—-因此永远不要形成循环。
6.1 Prevention
- Wait-die
- 老事务试图拿锁,锁在新事务中,老事务等新事务的锁;新事务试图拿锁,新事务直接die,进行rollback
- 新事务会变成老事务,事务在获得数据前可能会die几次
- Wound-wait
- 老事务要锁,锁在新事务时,新事务要rollback,把锁给老事务。新事务可能等老事务的锁。
- 新事务die的次数更少
6.2 死锁的判断
wait-for graph
Ti→Tj表示Ti在等Tj的锁被释放
如果有有向图中有环,那么有死锁
6.3 Deadlock Recovery
有些事务要rollback,要选择一个事务作为victim:
锁多的or锁少的
Rollback–rollback的方式
- Total rollback
- Partial rollback
7. Insert and Delete Operations
如果使用两相锁
- 删除元组的事务对要删除的元组有排他锁时,才可以执行删除操作。
- 向数据库中插入新元组的事务被赋予元组上的x模式锁
插入和删除可以导致幻影现象。
- 扫描关系的事务
- (例如,找出Perryridge所有账户的余额总和)以及在关系中插入元组的事务
- (例如,在Perryridge开设新帐户)(概念上)冲突,尽管没有访问任何共同的元组。
- 如果只使用元组锁,可能会导致不可序列化的调度例如,扫描事务不会看到新的帐户,而是读取更新事务写入的其他一些元组
- 扫描关系的事务
扫描关系的事务读取指示关系包含哪些元组的信息,而插入元组的事务更新相同的信息。
- 信息应该被锁定。
一个解决办法:
- 将数据项与关系关联,以表示有关关系包含哪些元组的信息。
- 扫描关系的事务获取数据项中的共享锁。
- 插入或删除元组的事务会获得数据项上的排他锁。(注意:数据项上的锁不会与单个元组上的锁冲突。)
上面的协议为插入/删除提供了非常低的并发性。
索引锁定协议提供了更高的并发性,同时通过要求在某些索引桶上加锁来防止幻影现象。
7.1 Index Locking Protocol
基于索引的加锁协议
基于某个属性的索引的加锁(如dept=”phy”),在查询、求和(select count(*) from r where dept=’phy’)等操作时,对应的数据被锁住,insert和delete在该index上无法进行。
Letuce 14 Recovery System
1. Failure Classification
Transaction failure
- Logical errors:overflow…
- system errors:deadlock…
System Crash
整个数据库系统死了,如停电、操作系统死了等…
重启后数据还在
Disk Failure
硬盘损坏,数据丢失等…
1.1 Recovery Algorithm
确保事务要么提交、要么rollback
- 正常的没出现failure时做一些准备
- 出现了failure进行恢复,确保原子性、一致性和持久性
2. Storage Structure
- Volatile Storage 易失性
- main memory,cache memory
- Nonvolatile Storage 非易失性
- 日志要存在这里面
- disk、tape、flash memory
2.1 Stable-Storage Implementation
Maintain multiple copies of each block on separate disks
多存几份数据
2.2 Data Access
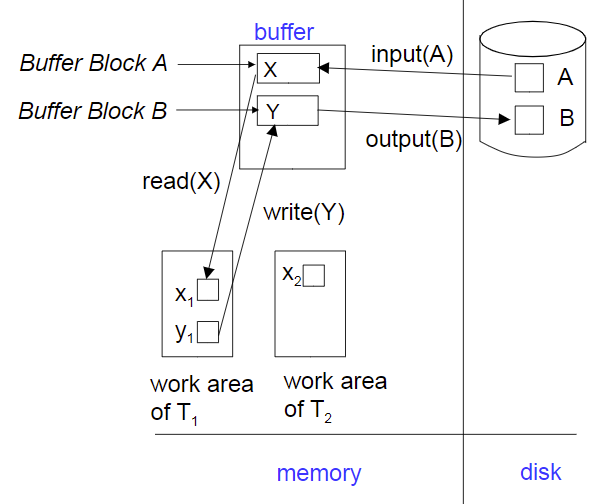
Physical Blocks是在硬盘里的
Buffer Blocks 是在main memory里的
有input 和 output 在两个区之间传输block
在事务执行时,Ti有自己独立的工作区,里面的数据是从buffer中复制的,设buffer中数据是X,Ti工作区内为Xi,read(X)是把Xi的值赋值为X,write(X)把X的值写成了Xi,但是output不一定马上执行,这样会很慢,在写入disk可以在buffer满时写入。
3. Recovery and Atomicity
4. 基于日志的恢复协议log-based recovery mechanisms
log只事务的开始、记录写回的东西、事务的提交
1 | <Ti,start>//T1开始了 |

只有commit之后的值需要改,否则不需要修改硬盘的值。
直接修改数据库立即修改方案允许在事务提交之前,将未提交的事务更新到缓冲区或磁盘本身
我们假设日志记录是直接输出到稳定存储(稍后将看到如何在某种程度上延迟日志记录输出)
可以在事务提交之前或之后的任何时候将更新的块输出到稳定存储块的输出顺序可以与它们的写入顺序不同。
4.1 恢复算法
undo
把没有提交的事务回滚,有start,但是没有commit或abort
redo
把修改重新做,有start,有commit或abort,为什么要redo?因为我们不知道commit后有没有写到磁盘上,我们就再修改一次。
4.1.1 CheckPoint
检查点的引入,我们不清楚什么时候写到硬盘上,因此
- 我们的搜索过程太耗时
- 大多数的重做事务已经写入硬盘了,但是还是要重做,使得恢复时间变长
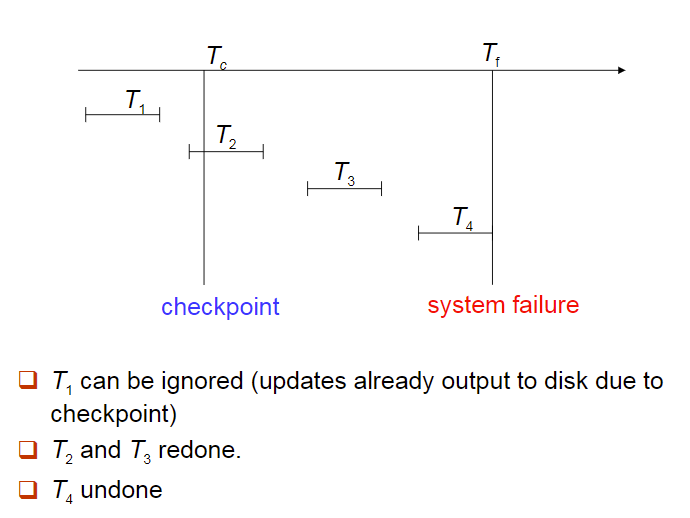
检查点的机制
在检查点操作过程中不允许执行任何更新,在执行检查点的过程中所有的缓存全部写到硬盘上。执行过程:
- 将位于主存的所有日志记录输出到稳定储存器;
- 所有修改过的缓冲块输出到硬盘。
- 在日志中加入
的日志记录,L是活跃状态的事务列表。
4.1.2 恢复处理
要找到哪些事务被正常提交了,哪些没有被提交。
正常提交:redo
没有提交:undo
第一步:找list
- 初始化undolist和redolist
- 从break掉的地方开始往回找,到checkpoint
- 某些日志commit了就把T放入redolist
- 某个日志start了,但是不在redolist,加入undolist
- 某个日志abort了,加入undolist
- 所有的Ti不在redolist中就放入undolist中
- 现在我们得到了undolist和redolist
第二步:进行undo
- 回倒,回滚
- 直到undolist中事务的start,不是到checkpoint就可以了
第三步:进行redo
- 从checkpoint开始redo,因为checkpoint已经写在硬盘上了
4.2 Buffer Management —Log Record Buffering

日志数据更重要。
只有Ti commit这条日志写到硬盘上,Ti才算提交了。
先写日志规则。
No-Force Policy
Force Policy:commit的时候同时写到硬盘上,花费很大
Steal Policy:恢复算法支持窃取策略,也就是说,包含未提交事务更新的块可以被写入磁盘,甚至在事务提交之前
当有未提交更新的块被输出到磁盘时,带更新撤销信息的日志记录会先输出到稳定存储的日志中(提前写日志)
当一个块输出到磁盘时,它不应该有任何更新正在进行。可以保证如下。
- 在写入数据项之前,事务获取包含该数据项的块上的独占锁
- 一旦写操作完成,锁就可以被释放。
- 这种保持时间较短的锁称为锁存。
将一个块输出到磁盘
- 首先获得一个专属的门闩
- 确保块上没有正在进行的更新
- 然后执行日志刷新
- 然后将块输出到磁盘
- 最后松开木块上的门闩
数据库缓冲区也可以实现
- 在为数据库预留的实际主内存区域中,或者在虚拟内存中
在保留的主内存中实现缓冲区有缺点:
- 内存事先在数据库缓冲区和应用程序之间进行分区,限制了灵活性。
- 需求可能会改变,尽管操作系统在任何时候都最清楚应该如何划分内存,但它不能改变内存的分区。
5. Advanced Recovery Techniques
支持高并发锁定技术
例如用于B +树并发控制
像B*-tree插入和删除这样的操作会提前释放锁。
它们不能通过恢复旧值(物理撤销)来撤销,因为一旦一个锁被释放,其他事务可能已经更新了B+树。
相反,插入(分别地。删除)通过执行删除(对应的。插入操作(称为逻辑撤消)。
对于此类操作,需要在undo日志记录中记录需要执行的undo操作
与物理撤消日志记录相反,称为逻辑撤消日志记录。
即使对于这样的操作,重做信息也会被物理地记录下来(即,每次写入的新值)
逻辑重做非常复杂,因为磁盘上的数据库状态可能不是“操作一致”的。

逻辑日志记录更改情况,比物理日志更好,可以实现交互。恢复时执行且执行一次。
Fuzzy CheckPoint
模糊检查点:
- 由于普通的检查点会呆在那里写硬盘,所以要避免这个问题。在没有请求的时候写入,即加入一个可选择的写入时间。
- 还是有一堆checkpoint,把要做的事情记录下来,但是不是真的干,等到数据库有空的时候再做,在last checkpoint上加一个指针,指向最后干完的checkpoint。
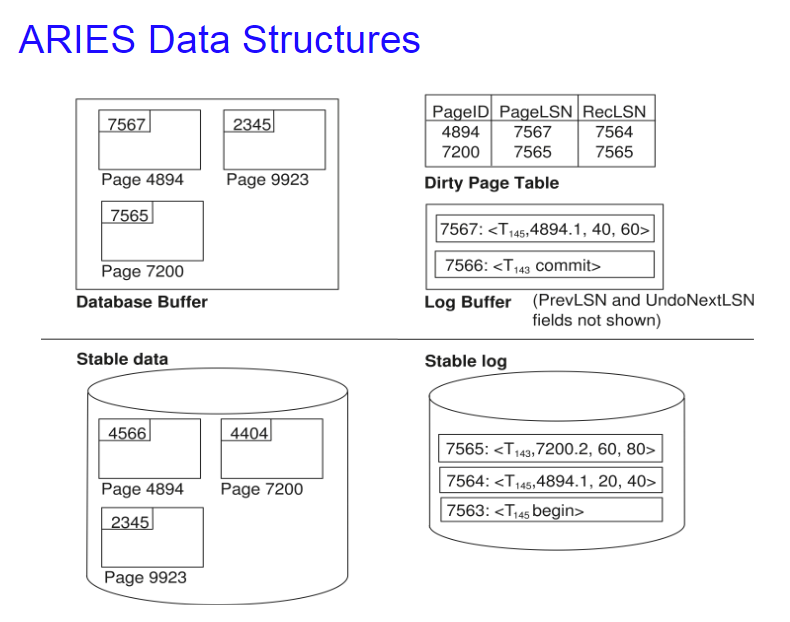
6. ARIES
- 每条日志有个编号LSN
- 是一个逻辑日志
- 维护一个Dirty Page,只关注内存和硬盘不同的block
- Fuzzy checkpoint只管制dirty page,不要求dirty page再checkpoint立即写入

6.1 PageLSN
PageLSN是一个page的最后一次的log的LSN。
要修改一个Page
- 拿一把Xlock
- update the page
- 把PageLSN更新
- unlock
6.2 Dirty Page Table
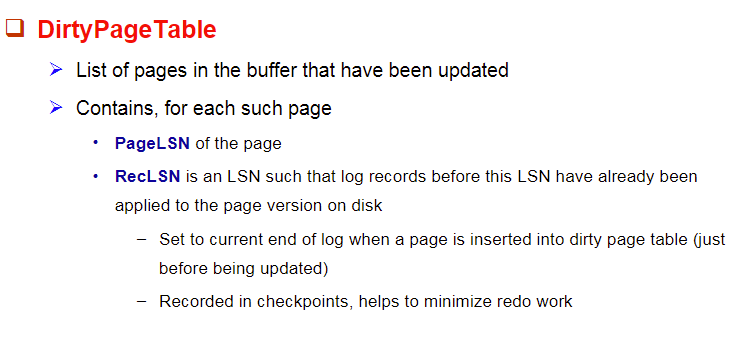
RecLSN最早的没写进硬盘的LSN
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !